CPU / 中央處理器
老黃x蘇媽 合力打造世界最強DGX A100超級電腦,牙膏廠掰掰! ft. GTC 2020重點介紹
文.圖/Johan 2020-05-15 17:30:00
NVIDIA正式於台北時間5月15日舉辦的GTC 2020 (GPU技術大會2020),CEO黃仁勳在自宅的廚房進行線上演說,主要也順便呼籲當今疫情嚴峻,待在家裡最好!也順便向抗疫英雄們致上最高敬意!
在這場GPU技術盛宴中,老黃端出自家最新DGX A100數據中心級伺服器,並展示其元件構成,包含世界最強大基於台積電7nm製程、Ampere架構的A100 GPU,並提及其伺服器運用到AMD的Rome CPU (即第二代EPYC伺服器處理器),兩強聯手打造出真正「地表最強」的資料中心級伺服器,就連蘇媽也在Twitter恭賀NVIDIA發表的最新產品,有用到她們家的CPU!牙膏廠可說是在HPC市場中,真正被放鳥!
 NVIDIA最新的DGX A100超級電腦系統,是由NVIDIA自家A100處理器,搭配AMD的EPYC處理器組合而成 (圖合成/PCDIY!)
NVIDIA最新的DGX A100超級電腦系統,是由NVIDIA自家A100處理器,搭配AMD的EPYC處理器組合而成 (圖合成/PCDIY!)
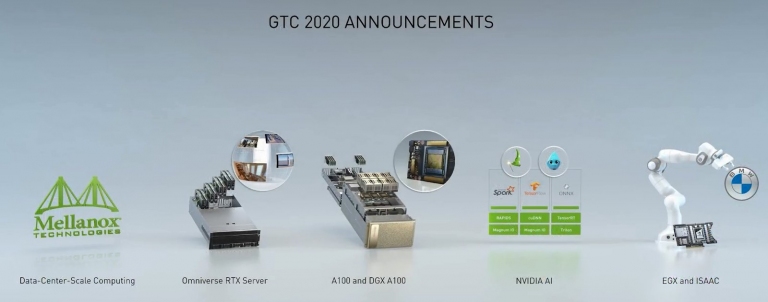
NVIDIA的GPU技術大會,主要區分為5大部份,包含從數據中心級的運算,到可協作的RTX伺服器遠距利用,當然還有今天的主角:A100 GPU與DGX A100伺服器,以及運用該伺服器所做到的三層AI運用,最後則是EGX智慧物連網的邊緣AI運算以及ISSAC智慧機器人等應用。
GTC 2020主題演說的5大重點
在這次的主力產品中,主要有上述採用TSMC 7nm製程生產的A100 GPU,為最新Ampere GPU架構,但是並沒有公佈消費級的RTX 3000系列,因此這場GTC 2020大會中,幾乎都是B2B的產品為主,市場也以專業繪圖、醫學、生技、工程、科學、數學、AI(人工智慧)、零售、工廠、車用、智慧物聯…等領域為主。以下藉由簡報內容,來快速了解這次NVIDIA到底「端出」什麼菜。
這次老黃帶領大家到他家廚房,來看這次GTC 2020主題演說將端出什麼菜
NVIDIA幫助醫療院所一同對抗新冠肺炎(COVID-19),已有多項計畫進行中
NVIDIA在每個領域都有其加速運算解決方案,從RTX、HGX、DGX、EGX到AGX (消費端、聚合端、數據中心端、邊緣運算端、自主機器端)
NVIDIA推動「加速運算」已有25年的歷程。包含GPU加速、全軟體堆疊、系統建構,到單一架構,打造完整生態圈
因此,NVIDIA先前併購Mellanox的用意,就是建構處理器之間的高速公路,也就是網路系統。Mellanox推出的高速智慧交換器與無線網卡,剛好可以滿足NVIDIA數據中心級伺服器在高速資料互連的需求。有關於這次發表的高速網卡產品,可以參考這裡。
老黃端出超大網路交換器
就是這台:Mellanox SN4700,擁有32埠的400GbE網路埠!
而這張卡就是:Mellanox ConnectX 6 Lx 智慧網卡,擁有2組25Gb/s埠,提供共50Gb/s的頻寬 (你買的新主機板可能最多只有到2.5GbE、5GbE或10GbE而已)。這張卡也會在後面的DGX A100看到
以下來看RTX伺服器在各領域的應用。
在開始說明之前,NVIDIA提到其CUDA架構,已經應用於各種行業需求,打造出超強健的軟體生態系,目前已推出50種新的SDK (軟體開發工具)
NVIDIA RTX主要提供專業繪圖領域最強的即時光追與AI,搭配深度學習,可以讓一個540p的畫面upscale到1080p,提供更清晰的影像
這是原生720p的畫面
這是其Ground Truth 16K的畫面
隆重介紹NVIDIA Omniverse,一套設計工作流程協作平台,支援各種作業系統
這裡說明,透過Quadro Virtual Workstation,就可以一台伺服器讓多人遠距執行各種專業軟體,並將最後的繪製成果結合起來。先前我們PCDIY!專訪過的夢想動畫,也是採用這類的平台來達到遠距ren圖的目標
現場展示以RTX伺服器協作平台,搭配光追特效與DLSS,所製作出的Cg等級遊戲:Marbles RTX (類似以前Marble Madness的遊戲,但這次的就好像在真實世界場景一樣)
超寫實的畫面,這都是NVIDIA Omniverse所提供的特色
程式設計師可以與其他人協作,來執行控制(移動)彈珠
這是老黃的雕像嗎? XD
是的!這個動畫展示,就叫做Marbles RTX。不曉得遊戲版何時上市
Marbles RTX的示範畫面,即時光追與DLSS的極致運用
這個Marbles RTX動畫展示,就是使用搭載Quadro RTX 8000專業繪圖卡的RTX Server做繪製出來的
NVIDIA表示當今很多大量資料與高效能運算應用,都可以靠GPU來達成。而NVIDIA也在建構這部份的軟體生態系,提供多種CUDA加速平台,讓效能提升。並且ARM架構伺服器也能用。並有I/O加速架構、基因學、資料分析等模型,讓以應用於科學領域
以往在ETL這個部份,都是以CPU來處理…
不過現在這個情況即將改觀,NVIDIA也透過其RAPIDS資料分析平台,來幫Apache Spark 3.0進行GPU加速運算,也就是以往透過CPU來處理資料庫的作法,現在也能透過GPU來加速運算。因此NVIDIA的三層AI框架,幾乎可以透過GPU來加速。
現在NVIDIA提供RAPIDS資料分析平台,透過GPU來幫助Apache Spark 3.0加速ETL的大數據處理
這次,NVIDIA GPU支援開源社群,加快Spark 3.0的運算速度,讓ETL與SQL的處理,能以飛快的速度,處理數百TB的海量資料,讓Adobe在Databricks上使用Spark 3.0訓練模型時,速度可以提高7倍!詳細內容可以參考這裡。
以前使用18台2U伺服器系統,佔用兩櫃,16千瓦的電,共100萬美元的費用,在處理TPCx-BB@SF 10K資料時,只能做到17GB/s的資料量
現在只要16台DGX-1伺服器,同樣佔用兩櫃,56千瓦的電,共200萬美元的費用,就可以處理163GB/s的資料量
花2倍的費用,卻能得到將近10倍的效能提升。整體下來等於是5倍的價格效能比
若要單純用CPU來處理,也要達到163GB/s的效能。那可得花1千萬美元的費用,建置167台2U的伺服器系統,將使用到11櫃了!吃電也要吃到140千瓦
因此,將CPU改成GPU處理,可省1/5的成本,以及1/3的電費
上面講的是第一層的大數據資料處理階段,接下來講第二層的訓練階段。這部份NVIDIA有推出其Merlin框架,是一款深度推薦應用框架,可協助零售業來分析消費者行為,並將其喜好餵給AI,以得到最確切的選購推薦。這部份當然也可以透過GPU來加速運算,透過ETL+Training都用GPU來算的話,速度比以前用CPU時還快到不可思議!
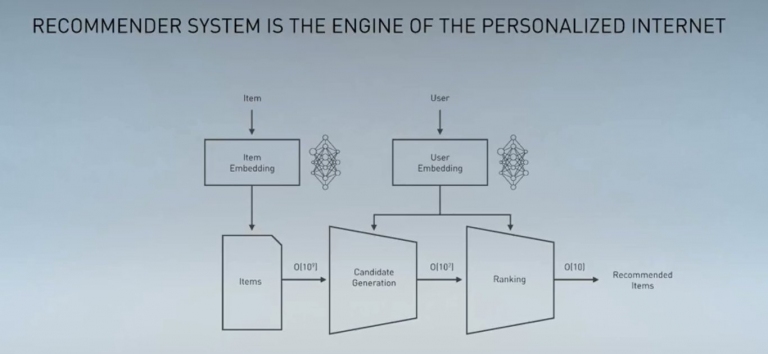
推薦系統,是個人化網路內容的引擎,這裡是架構圖
新的NVIDIA Merlin框架,就是可以幫助零售業者來加速訓練。以往使用CPU來做訓練時,ETL階段就要2小時,訓練完要花1天半,若改用GPU的話,ETL階段只要3分鐘,而訓練也只要16分鐘,這真是快到不可思議的速度!
第三層就是「推論」,NVIDIA也推出其新的Jarvis應用程式框架,詳細內容可參考這裡。
NVIDIA發表Jarvis框架,一種多模態對話式AI服務框架。搭Onmiverse圖像化,可打造出企業自己的Siri等級智慧對話機器人
就是可以幫助零售業者來加速訓練。以往使用CPU來做訓練時,ETL階段就要2小時,訓練完要花1天半,若改用GPU的話,ETL階段只要3分鐘,而訓練也只要16分鐘,這真是快到不可思議的速度!
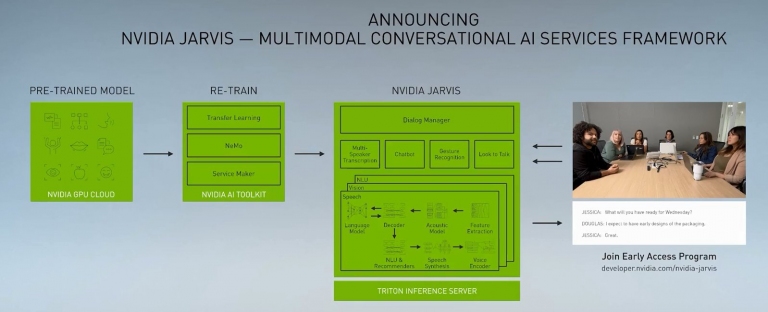
以GPU加速的NVIDIA Jarvis應用程式框架,讓企業能夠透過影片與語音資料來為各自產業、產品和客戶打造客製化的先進對話式人工智慧(AI)服務,屆時就能打造屬於企業專屬的智慧對話機器人(類似Siri),甚至可以圖像化,讓對話更加擬人化。
NVIDIA Jarvis框架系統架構圖
對話式AI正在改變產業型態。包括視訊會議系統、客服中心、智慧喇叭、零售店輔銷員、車用語音輔助精靈等等
以上就是NVIDIA AI的三層框架,全部都已可以透過GPU來進行加速運算
為此,NVIDIA鄭重發表這次的主角,也就是A100 GPU,這款全新的數據中心級GPU,採用TSMC 7nm製程設計,Ampere架構,具備540億電晶體,內建HBM2記憶體,提供高達1.6 TB/s頻寬。並具有新的TF32 Tensor Core指令架構,比FP32快上加快!詳細規格可以參考這裡。
NVIDIA正式發表A100 GPU,當今最強悍的處理器
具備全新TF32 Tensor核心,此為資料格式比較
跟上一代Volta架構的V100相比,Ampere架構的A100 GPU,在BERT Training的效能快上6倍,在BERT Inference更快7倍。其搭配尖峰效能,在各式加速運算的效能,最高可以快上20倍!
此外搭配A100來計算,相較於V100來說,尖峰效能可達20倍!
此外,老黃更從烤箱裡「端出」以A100 GPU所打造的DGX A100伺服器,詳細規格可以參考這裡。
老黃正式將DGX A100伺服器「端出爐」
DGX A100伺服器主機,含有8顆A100 GPU,旁邊則是6組NVSwitch資料交換晶片
A100具有新的多重範本設計,賦予彈性的GPU運算應用。每GPU在同步執行範本的資料傳輸率,是V100的7倍!
隆重介紹:NVIDIA DGX A100伺服器,為第三代整合AI系統。單節點效能高達5 PetaFLOPS!
裡面構造解說:具有雙顆64核AMD EPYC Rome伺服器處理器、1TB的記憶體、8顆NVIDIA A100 GPU、6顆NVIDIA NVSwitch頻寬切換晶片(提供雙向4.8TB/s頻寬,GPU至GPU頻寬達600GB/s),並內建15TB的PCIe 4.0 NVMe SSD,此外還有9埠Mellanox ConnectX-6 VPI網路晶片提供高達200Gb/s的網路頻寬
先看GPU:內建8顆A100 GPU,每顆內建40GB記憶體,因此總共有320GB的HBM2記憶體,且每GPU含有12組NVLink,具備600GB/s的GPU至GPU傳輸頻寬
再看內部互連機制:內建6顆NVSwitch晶片,提供雙向4.8TB/s頻寬
裝了8片Mellanox ConnectX-6 VPI HDR InfiniBand/200 GbE網路卡,提供叢集運算,總共具有200GB/s的尖峰效能。另有1埠雙埠ConnectX-6是用來進行資料/儲存網路使用
這就是DGX A100伺服器主機,外面還鑲金呢
以上就是NVIDIA DGX A100世界上最先進的伺服器系統,可用來處理所有的AI工作
這裡是DGX A100效能簡述:INT8具備10 PetaOPS尖峰效能、FP16具備5 PetaOPS尖峰效能、TF32具備2.5 PetaOPS尖峰效能、FP64則高達156 PetaOPS尖峰效能
相較於高效能CPU伺服器,這台DGX A100具備150倍的AI運算效能、40倍的記憶體頻寬與I/O頻寬。現已上市,售價為199,000美元 (拾玖點玖萬美元)
說到佔地面積與耗電量部分,當今AI數據中心配置50台DGX-1系統(用來做AI訓練)、600台CPU系統(用來做AI推論),總共需要耗資1千1百萬美元,佔地25櫃,耗電達630千瓦
改用DGX A100之後,只要買5台就夠了!耗資僅1百萬美元,佔地僅1櫃,耗電量僅28千瓦。設備成本才1/10,電費也只有1/20!
若以Pagerank案例來算,一般資料爬蟲應用,以2.6TB Graph – 128百萬Edge 資料量來算,就要配置3千台CPU伺服器,佔地105櫃。效能為52百萬Edges/秒
若改用DGX A100伺服器,只要4台即可。效能達到688百萬Edges/秒。整體效能提升13倍,成本僅1/75
此外,NVIDIA也打造700 Petaflops的次世代 DGX SuperPOD,幫助客戶在AI工作流程中運用經驗證的企業級軟體。這些SuperPOD都是配備DGX A100伺服器,以充分發揮伺服器房的坪效。
NVIDIA也發表新的DGX A100 SuperPOD,可建置高達140台伺服器機櫃系統,數據中心要建置一列機櫃、提供高達700 PFLOPSAI效能,也只要3週即可施工完成
未來擴充後總效能可以達到4.6 ExaFLOPS,要標下3~4件美國國家實驗室的Exascale超級電腦標案,也不是問題了XD
至於EGX Jetson Xavier NX開發套件,細節可以參考這裡。
隆重介紹:NVIDIA EGX A100搭配Mellanox CX6 DX模組,主打邊緣AI運算
各部位介紹:內建一顆Ampere GPU,採用第三代Tensor Core架構,具備機密AI必要的新安全引擎、安全認證開機機制。ConnectX-6 DX網卡,提供兩埠100Gb/s的傳輸頻寬
這是搭載NVIDIA EGX平台的ISSAC機器人工廠與Aerial 5G的CloudRAN(雲端無線接取網路)系統架構圖
BMW選擇NVIDIA的ISSAC機器人平台,做為其汽車製造工廠的平台。有關於這部份的細節,可以參考這裡
NVIDIA的EGX生態系,跨足了不同產業,此為合作夥伴列表。裡面比較熟悉的台灣廠商,就是台積電和鴻海了
至於在車載應用方面,NVIDIA也展示搭配新的Ampere架構GPU,將讓自駕車的等級從第2級直接跳級升到第5級,也就是無人駕駛載客等級!
有關於NVIDIA Drive AV視覺化系統,從感測、感知到繪製、計畫,到自駕,都是環環相扣的。需要有強大的車用電腦運算能力,才能達成
NVIDIA Drive車用電腦,從最早Orin架構,到最新的Ampere架構。讓最早只能做到ADAS(先進駕駛輔助系統)、先前第2級的自駕系統,到現在的第5級自駕載客車系統
現在都流行所謂的軟體定義xx平台,而NVIDIA Drive就是軟體定義自駕平台。從資料蒐集、模型訓練、駕駛模擬,到真正上路自駕,都能一個平台全部搞定
左為模擬駕駛的畫面,右邊為真實上路的畫面。GTC 2020也展示其已經可以順利自駕成功
這就是NVIDIA Drive全球生態系與夥伴列表
老黃:您的廚房有很多吃的,我的廚房有199K美元的數據中心伺服器! (設計對白/PCDIY!)
以上就是GTC 2020的主題演講重點內容介紹,想了解更多GTC 2020主體演講細節,可移駕到NVIDIA官網。
在這場GPU技術盛宴中,老黃端出自家最新DGX A100數據中心級伺服器,並展示其元件構成,包含世界最強大基於台積電7nm製程、Ampere架構的A100 GPU,並提及其伺服器運用到AMD的Rome CPU (即第二代EPYC伺服器處理器),兩強聯手打造出真正「地表最強」的資料中心級伺服器,就連蘇媽也在Twitter恭賀NVIDIA發表的最新產品,有用到她們家的CPU!牙膏廠可說是在HPC市場中,真正被放鳥!
 NVIDIA最新的DGX A100超級電腦系統,是由NVIDIA自家A100處理器,搭配AMD的EPYC處理器組合而成 (圖合成/PCDIY!)
NVIDIA最新的DGX A100超級電腦系統,是由NVIDIA自家A100處理器,搭配AMD的EPYC處理器組合而成 (圖合成/PCDIY!)NVIDIA的GPU技術大會,主要區分為5大部份,包含從數據中心級的運算,到可協作的RTX伺服器遠距利用,當然還有今天的主角:A100 GPU與DGX A100伺服器,以及運用該伺服器所做到的三層AI運用,最後則是EGX智慧物連網的邊緣AI運算以及ISSAC智慧機器人等應用。
 GTC 2020主題演說的5大重點
GTC 2020主題演說的5大重點在這次的主力產品中,主要有上述採用TSMC 7nm製程生產的A100 GPU,為最新Ampere GPU架構,但是並沒有公佈消費級的RTX 3000系列,因此這場GTC 2020大會中,幾乎都是B2B的產品為主,市場也以專業繪圖、醫學、生技、工程、科學、數學、AI(人工智慧)、零售、工廠、車用、智慧物聯…等領域為主。以下藉由簡報內容,來快速了解這次NVIDIA到底「端出」什麼菜。
 這次老黃帶領大家到他家廚房,來看這次GTC 2020主題演說將端出什麼菜
這次老黃帶領大家到他家廚房,來看這次GTC 2020主題演說將端出什麼菜向抗疫英雄致敬,NVIDIA擴大推動醫療合作計畫,協助基因定序
NVIDIA CEO黃仁勳首先向COVID-19抗疫英雄們致敬,並簡介其加入全球醫療合作夥伴的,詳細新聞可以參考這裡。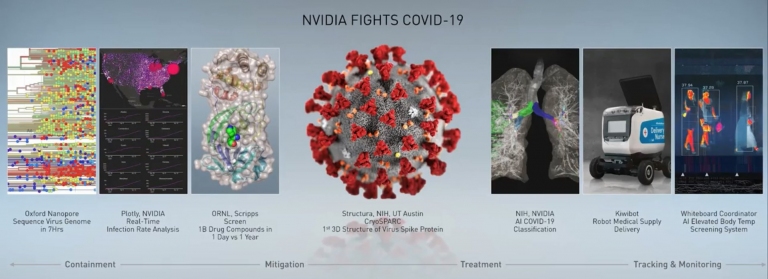 NVIDIA幫助醫療院所一同對抗新冠肺炎(COVID-19),已有多項計畫進行中
NVIDIA幫助醫療院所一同對抗新冠肺炎(COVID-19),已有多項計畫進行中推動資料中心級運算,NVIDIA發表Mellanox智慧交換器與網卡
由於數據中心都是平行運算,除了CPU和GPU要夠快,其之間的通訊也要夠快才行,因此要搭配超強的智慧網卡與智慧交換器,才能將運算好的資料結果與其他處理器溝通,以完成各種密集運算。 NVIDIA在每個領域都有其加速運算解決方案,從RTX、HGX、DGX、EGX到AGX (消費端、聚合端、數據中心端、邊緣運算端、自主機器端)
NVIDIA在每個領域都有其加速運算解決方案,從RTX、HGX、DGX、EGX到AGX (消費端、聚合端、數據中心端、邊緣運算端、自主機器端)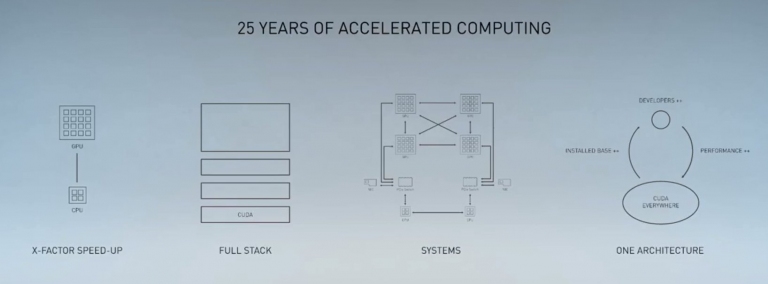 NVIDIA推動「加速運算」已有25年的歷程。包含GPU加速、全軟體堆疊、系統建構,到單一架構,打造完整生態圈
NVIDIA推動「加速運算」已有25年的歷程。包含GPU加速、全軟體堆疊、系統建構,到單一架構,打造完整生態圈因此,NVIDIA先前併購Mellanox的用意,就是建構處理器之間的高速公路,也就是網路系統。Mellanox推出的高速智慧交換器與無線網卡,剛好可以滿足NVIDIA數據中心級伺服器在高速資料互連的需求。有關於這次發表的高速網卡產品,可以參考這裡。
 老黃端出超大網路交換器
老黃端出超大網路交換器 就是這台:Mellanox SN4700,擁有32埠的400GbE網路埠!
就是這台:Mellanox SN4700,擁有32埠的400GbE網路埠! 而這張卡就是:Mellanox ConnectX 6 Lx 智慧網卡,擁有2組25Gb/s埠,提供共50Gb/s的頻寬 (你買的新主機板可能最多只有到2.5GbE、5GbE或10GbE而已)。這張卡也會在後面的DGX A100看到
而這張卡就是:Mellanox ConnectX 6 Lx 智慧網卡,擁有2組25Gb/s埠,提供共50Gb/s的頻寬 (你買的新主機板可能最多只有到2.5GbE、5GbE或10GbE而已)。這張卡也會在後面的DGX A100看到Omniverse RTX Server,推動遠距協作圖形工作平台
由於當今繪圖工作站,需要更即時、更強大的加速運算伺服器,且還要能達到協作需求,因此NVIDIA推出了Omniverse全方位RTX Server,就是針對各種專業繪圖領域的企業所量身打造,賦予專業人士們來建造未曾存在於世界上的擬真場景。以下來看RTX伺服器在各領域的應用。
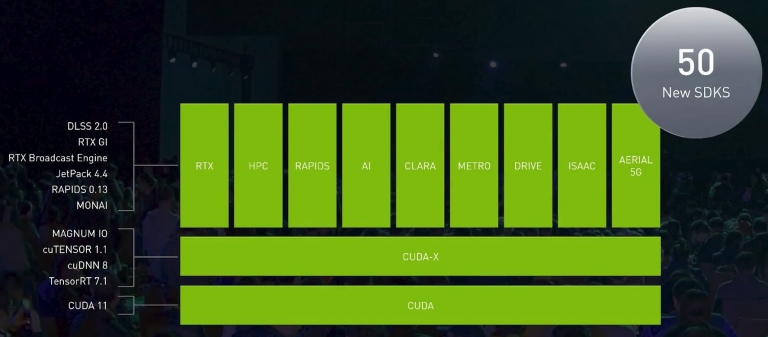 在開始說明之前,NVIDIA提到其CUDA架構,已經應用於各種行業需求,打造出超強健的軟體生態系,目前已推出50種新的SDK (軟體開發工具)
在開始說明之前,NVIDIA提到其CUDA架構,已經應用於各種行業需求,打造出超強健的軟體生態系,目前已推出50種新的SDK (軟體開發工具)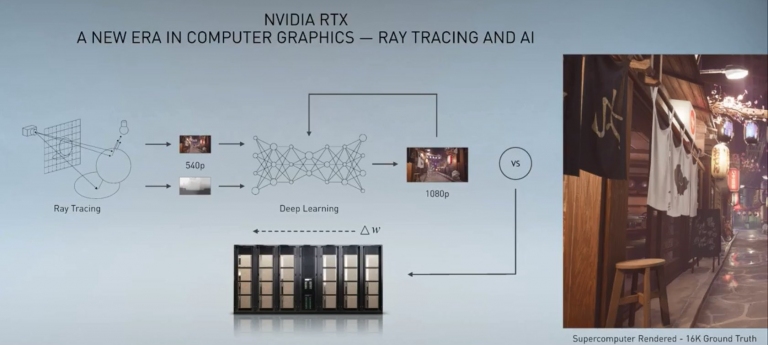 NVIDIA RTX主要提供專業繪圖領域最強的即時光追與AI,搭配深度學習,可以讓一個540p的畫面upscale到1080p,提供更清晰的影像
NVIDIA RTX主要提供專業繪圖領域最強的即時光追與AI,搭配深度學習,可以讓一個540p的畫面upscale到1080p,提供更清晰的影像 這是原生720p的畫面
這是原生720p的畫面 這是其Ground Truth 16K的畫面
這是其Ground Truth 16K的畫面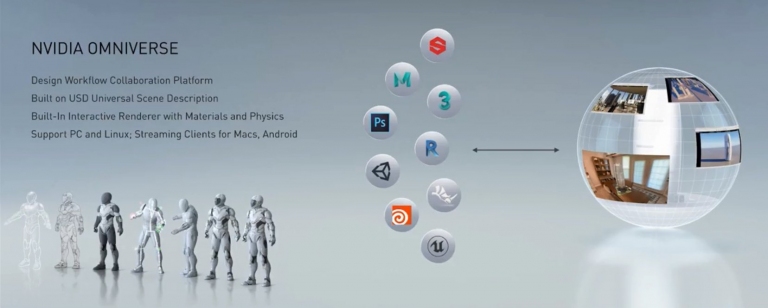 隆重介紹NVIDIA Omniverse,一套設計工作流程協作平台,支援各種作業系統
隆重介紹NVIDIA Omniverse,一套設計工作流程協作平台,支援各種作業系統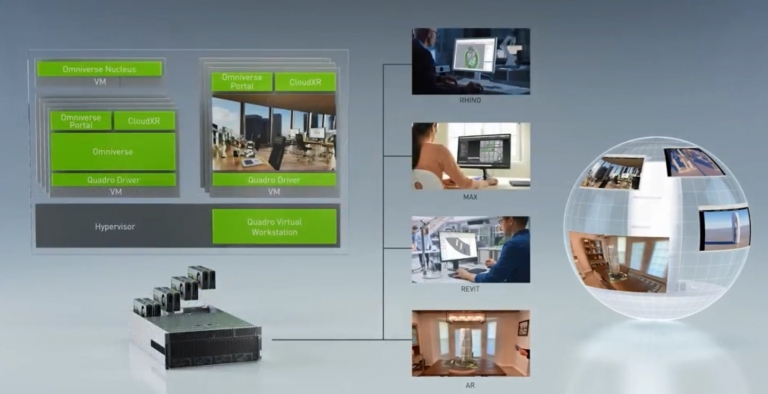 這裡說明,透過Quadro Virtual Workstation,就可以一台伺服器讓多人遠距執行各種專業軟體,並將最後的繪製成果結合起來。先前我們PCDIY!專訪過的夢想動畫,也是採用這類的平台來達到遠距ren圖的目標
這裡說明,透過Quadro Virtual Workstation,就可以一台伺服器讓多人遠距執行各種專業軟體,並將最後的繪製成果結合起來。先前我們PCDIY!專訪過的夢想動畫,也是採用這類的平台來達到遠距ren圖的目標 現場展示以RTX伺服器協作平台,搭配光追特效與DLSS,所製作出的Cg等級遊戲:Marbles RTX (類似以前Marble Madness的遊戲,但這次的就好像在真實世界場景一樣)
現場展示以RTX伺服器協作平台,搭配光追特效與DLSS,所製作出的Cg等級遊戲:Marbles RTX (類似以前Marble Madness的遊戲,但這次的就好像在真實世界場景一樣) 超寫實的畫面,這都是NVIDIA Omniverse所提供的特色
超寫實的畫面,這都是NVIDIA Omniverse所提供的特色 程式設計師可以與其他人協作,來執行控制(移動)彈珠
程式設計師可以與其他人協作,來執行控制(移動)彈珠 這是老黃的雕像嗎? XD
這是老黃的雕像嗎? XD 是的!這個動畫展示,就叫做Marbles RTX。不曉得遊戲版何時上市
是的!這個動畫展示,就叫做Marbles RTX。不曉得遊戲版何時上市Marbles RTX的示範畫面,即時光追與DLSS的極致運用
 這個Marbles RTX動畫展示,就是使用搭載Quadro RTX 8000專業繪圖卡的RTX Server做繪製出來的
這個Marbles RTX動畫展示,就是使用搭載Quadro RTX 8000專業繪圖卡的RTX Server做繪製出來的NVIDIA的三層AI框架
當今數據中心要將既有的大數據資料,透過ETL (擷取、轉換、載入)程序,然後再餵給伺服器去做Training (訓練),最後才達到Inference (推論)步驟,將AI推導的結果呈現出來,要經過上述三步驟才行。後兩個步驟現在幾乎都是靠GPU來處理與實現,而NVIDIA也有對應的cuDNN和TensorRT解決方案,但在第一步驟則還是要倚靠CPU來處理,因此CPU也必須夠強大才行。 NVIDIA表示當今很多大量資料與高效能運算應用,都可以靠GPU來達成。而NVIDIA也在建構這部份的軟體生態系,提供多種CUDA加速平台,讓效能提升。並且ARM架構伺服器也能用。並有I/O加速架構、基因學、資料分析等模型,讓以應用於科學領域
NVIDIA表示當今很多大量資料與高效能運算應用,都可以靠GPU來達成。而NVIDIA也在建構這部份的軟體生態系,提供多種CUDA加速平台,讓效能提升。並且ARM架構伺服器也能用。並有I/O加速架構、基因學、資料分析等模型,讓以應用於科學領域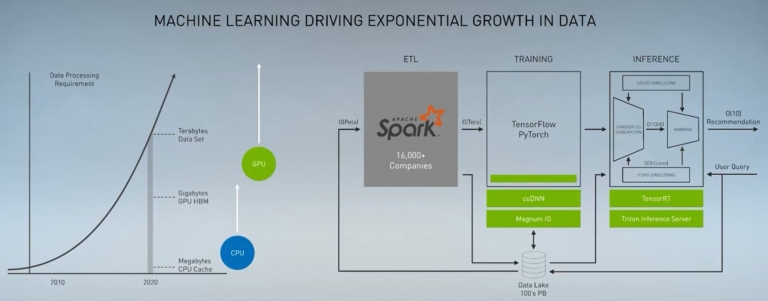 以往在ETL這個部份,都是以CPU來處理…
以往在ETL這個部份,都是以CPU來處理…不過現在這個情況即將改觀,NVIDIA也透過其RAPIDS資料分析平台,來幫Apache Spark 3.0進行GPU加速運算,也就是以往透過CPU來處理資料庫的作法,現在也能透過GPU來加速運算。因此NVIDIA的三層AI框架,幾乎可以透過GPU來加速。
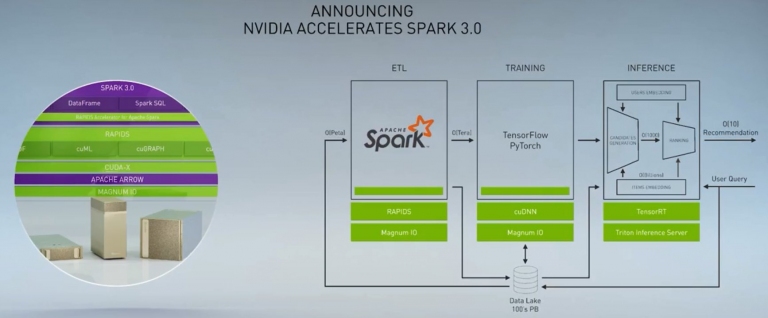 現在NVIDIA提供RAPIDS資料分析平台,透過GPU來幫助Apache Spark 3.0加速ETL的大數據處理
現在NVIDIA提供RAPIDS資料分析平台,透過GPU來幫助Apache Spark 3.0加速ETL的大數據處理這次,NVIDIA GPU支援開源社群,加快Spark 3.0的運算速度,讓ETL與SQL的處理,能以飛快的速度,處理數百TB的海量資料,讓Adobe在Databricks上使用Spark 3.0訓練模型時,速度可以提高7倍!詳細內容可以參考這裡。
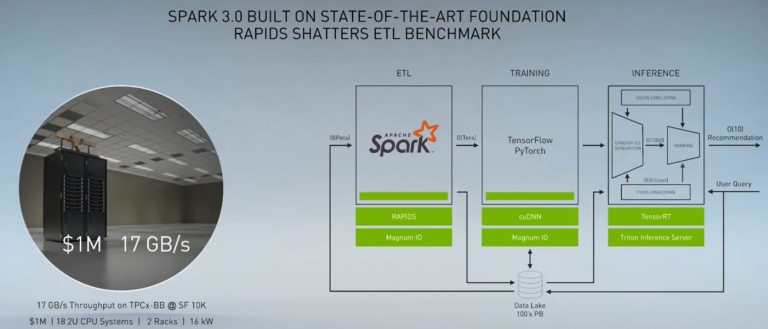 以前使用18台2U伺服器系統,佔用兩櫃,16千瓦的電,共100萬美元的費用,在處理TPCx-BB@SF 10K資料時,只能做到17GB/s的資料量
以前使用18台2U伺服器系統,佔用兩櫃,16千瓦的電,共100萬美元的費用,在處理TPCx-BB@SF 10K資料時,只能做到17GB/s的資料量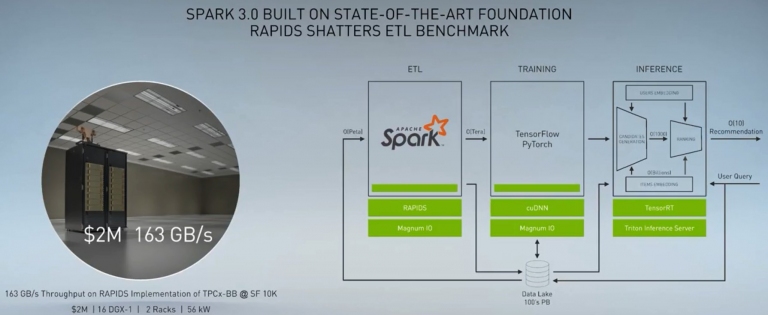 現在只要16台DGX-1伺服器,同樣佔用兩櫃,56千瓦的電,共200萬美元的費用,就可以處理163GB/s的資料量
現在只要16台DGX-1伺服器,同樣佔用兩櫃,56千瓦的電,共200萬美元的費用,就可以處理163GB/s的資料量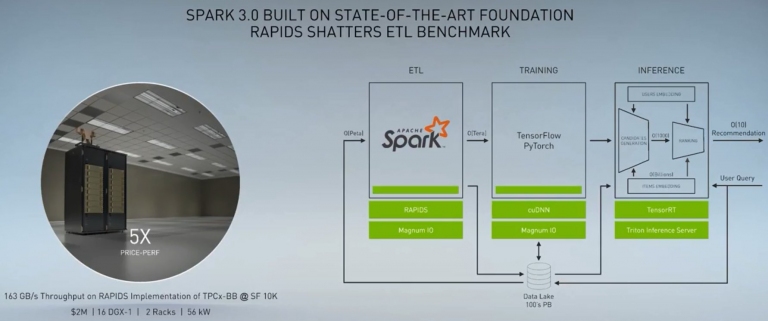 花2倍的費用,卻能得到將近10倍的效能提升。整體下來等於是5倍的價格效能比
花2倍的費用,卻能得到將近10倍的效能提升。整體下來等於是5倍的價格效能比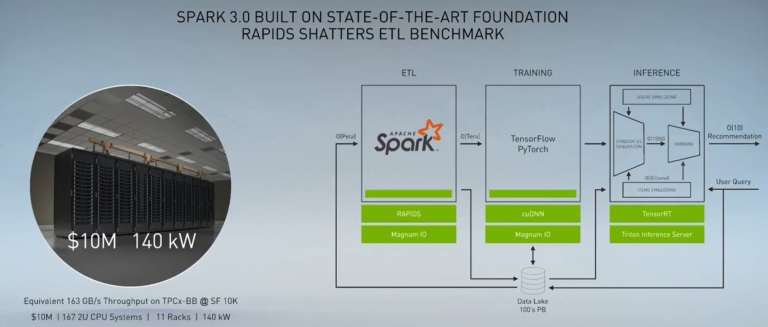 若要單純用CPU來處理,也要達到163GB/s的效能。那可得花1千萬美元的費用,建置167台2U的伺服器系統,將使用到11櫃了!吃電也要吃到140千瓦
若要單純用CPU來處理,也要達到163GB/s的效能。那可得花1千萬美元的費用,建置167台2U的伺服器系統,將使用到11櫃了!吃電也要吃到140千瓦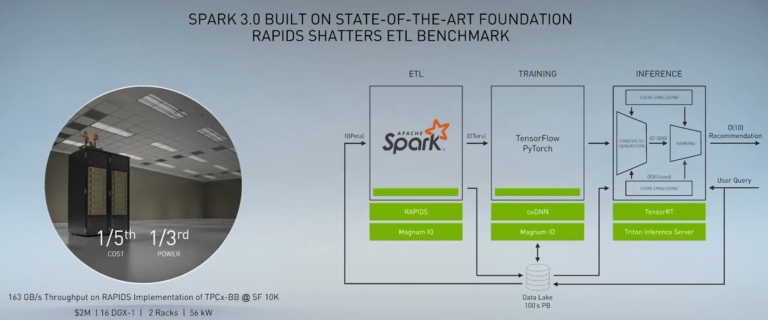 因此,將CPU改成GPU處理,可省1/5的成本,以及1/3的電費
因此,將CPU改成GPU處理,可省1/5的成本,以及1/3的電費上面講的是第一層的大數據資料處理階段,接下來講第二層的訓練階段。這部份NVIDIA有推出其Merlin框架,是一款深度推薦應用框架,可協助零售業來分析消費者行為,並將其喜好餵給AI,以得到最確切的選購推薦。這部份當然也可以透過GPU來加速運算,透過ETL+Training都用GPU來算的話,速度比以前用CPU時還快到不可思議!
 推薦系統,是個人化網路內容的引擎,這裡是架構圖
推薦系統,是個人化網路內容的引擎,這裡是架構圖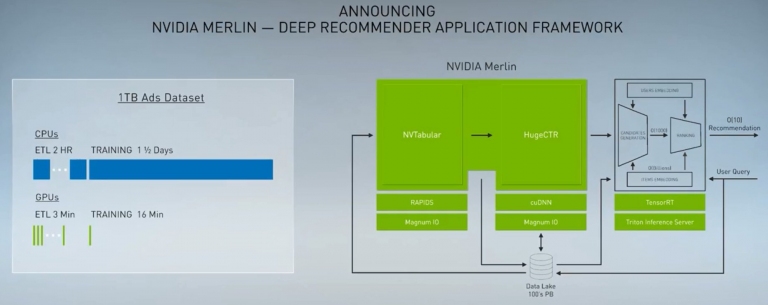 新的NVIDIA Merlin框架,就是可以幫助零售業者來加速訓練。以往使用CPU來做訓練時,ETL階段就要2小時,訓練完要花1天半,若改用GPU的話,ETL階段只要3分鐘,而訓練也只要16分鐘,這真是快到不可思議的速度!
新的NVIDIA Merlin框架,就是可以幫助零售業者來加速訓練。以往使用CPU來做訓練時,ETL階段就要2小時,訓練完要花1天半,若改用GPU的話,ETL階段只要3分鐘,而訓練也只要16分鐘,這真是快到不可思議的速度!第三層就是「推論」,NVIDIA也推出其新的Jarvis應用程式框架,詳細內容可參考這裡。
 NVIDIA發表Jarvis框架,一種多模態對話式AI服務框架。搭Onmiverse圖像化,可打造出企業自己的Siri等級智慧對話機器人
NVIDIA發表Jarvis框架,一種多模態對話式AI服務框架。搭Onmiverse圖像化,可打造出企業自己的Siri等級智慧對話機器人就是可以幫助零售業者來加速訓練。以往使用CPU來做訓練時,ETL階段就要2小時,訓練完要花1天半,若改用GPU的話,ETL階段只要3分鐘,而訓練也只要16分鐘,這真是快到不可思議的速度!
以GPU加速的NVIDIA Jarvis應用程式框架,讓企業能夠透過影片與語音資料來為各自產業、產品和客戶打造客製化的先進對話式人工智慧(AI)服務,屆時就能打造屬於企業專屬的智慧對話機器人(類似Siri),甚至可以圖像化,讓對話更加擬人化。
 NVIDIA Jarvis框架系統架構圖
NVIDIA Jarvis框架系統架構圖 對話式AI正在改變產業型態。包括視訊會議系統、客服中心、智慧喇叭、零售店輔銷員、車用語音輔助精靈等等
對話式AI正在改變產業型態。包括視訊會議系統、客服中心、智慧喇叭、零售店輔銷員、車用語音輔助精靈等等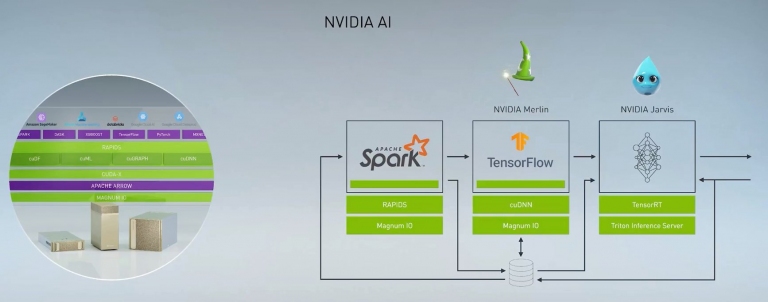 以上就是NVIDIA AI的三層框架,全部都已可以透過GPU來進行加速運算
以上就是NVIDIA AI的三層框架,全部都已可以透過GPU來進行加速運算發表資料中心級A100 GPU與DGX A100伺服器
正因為上述NVIDIA AI三個框架,都已全面運用到GPU來加速運算,在當今資料量越來越龐大的應用下,數據中心對於HPC的效能要求也希望能呈對比級數的增長,以減少伺服器的部署,同時降低TCO成本。為此,NVIDIA鄭重發表這次的主角,也就是A100 GPU,這款全新的數據中心級GPU,採用TSMC 7nm製程設計,Ampere架構,具備540億電晶體,內建HBM2記憶體,提供高達1.6 TB/s頻寬。並具有新的TF32 Tensor Core指令架構,比FP32快上加快!詳細規格可以參考這裡。
 NVIDIA正式發表A100 GPU,當今最強悍的處理器
NVIDIA正式發表A100 GPU,當今最強悍的處理器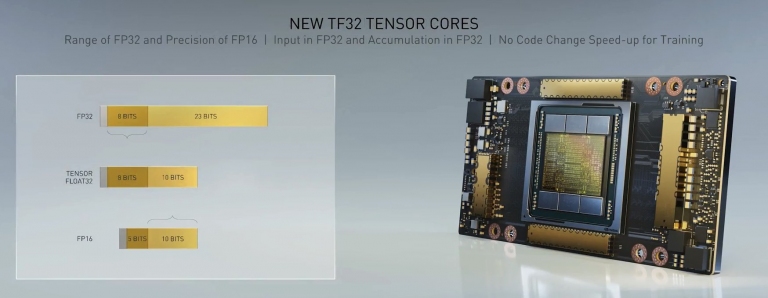 具備全新TF32 Tensor核心,此為資料格式比較
具備全新TF32 Tensor核心,此為資料格式比較跟上一代Volta架構的V100相比,Ampere架構的A100 GPU,在BERT Training的效能快上6倍,在BERT Inference更快7倍。其搭配尖峰效能,在各式加速運算的效能,最高可以快上20倍!
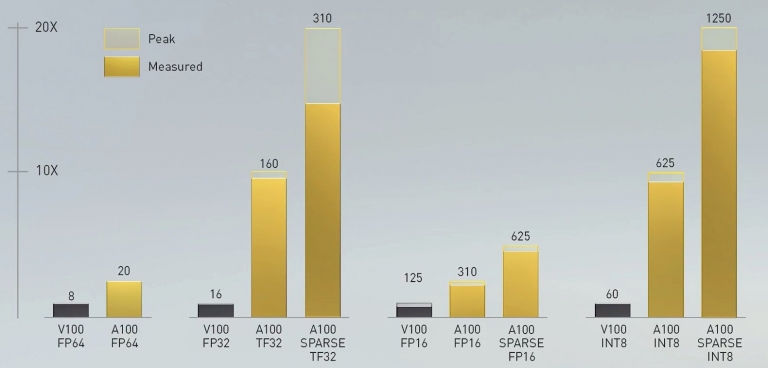 此外搭配A100來計算,相較於V100來說,尖峰效能可達20倍!
此外搭配A100來計算,相較於V100來說,尖峰效能可達20倍!此外,老黃更從烤箱裡「端出」以A100 GPU所打造的DGX A100伺服器,詳細規格可以參考這裡。
 老黃正式將DGX A100伺服器「端出爐」
老黃正式將DGX A100伺服器「端出爐」 DGX A100伺服器主機,含有8顆A100 GPU,旁邊則是6組NVSwitch資料交換晶片
DGX A100伺服器主機,含有8顆A100 GPU,旁邊則是6組NVSwitch資料交換晶片 A100具有新的多重範本設計,賦予彈性的GPU運算應用。每GPU在同步執行範本的資料傳輸率,是V100的7倍!
A100具有新的多重範本設計,賦予彈性的GPU運算應用。每GPU在同步執行範本的資料傳輸率,是V100的7倍! 隆重介紹:NVIDIA DGX A100伺服器,為第三代整合AI系統。單節點效能高達5 PetaFLOPS!
隆重介紹:NVIDIA DGX A100伺服器,為第三代整合AI系統。單節點效能高達5 PetaFLOPS! 裡面構造解說:具有雙顆64核AMD EPYC Rome伺服器處理器、1TB的記憶體、8顆NVIDIA A100 GPU、6顆NVIDIA NVSwitch頻寬切換晶片(提供雙向4.8TB/s頻寬,GPU至GPU頻寬達600GB/s),並內建15TB的PCIe 4.0 NVMe SSD,此外還有9埠Mellanox ConnectX-6 VPI網路晶片提供高達200Gb/s的網路頻寬
裡面構造解說:具有雙顆64核AMD EPYC Rome伺服器處理器、1TB的記憶體、8顆NVIDIA A100 GPU、6顆NVIDIA NVSwitch頻寬切換晶片(提供雙向4.8TB/s頻寬,GPU至GPU頻寬達600GB/s),並內建15TB的PCIe 4.0 NVMe SSD,此外還有9埠Mellanox ConnectX-6 VPI網路晶片提供高達200Gb/s的網路頻寬 先看GPU:內建8顆A100 GPU,每顆內建40GB記憶體,因此總共有320GB的HBM2記憶體,且每GPU含有12組NVLink,具備600GB/s的GPU至GPU傳輸頻寬
先看GPU:內建8顆A100 GPU,每顆內建40GB記憶體,因此總共有320GB的HBM2記憶體,且每GPU含有12組NVLink,具備600GB/s的GPU至GPU傳輸頻寬 再看內部互連機制:內建6顆NVSwitch晶片,提供雙向4.8TB/s頻寬
再看內部互連機制:內建6顆NVSwitch晶片,提供雙向4.8TB/s頻寬 裝了8片Mellanox ConnectX-6 VPI HDR InfiniBand/200 GbE網路卡,提供叢集運算,總共具有200GB/s的尖峰效能。另有1埠雙埠ConnectX-6是用來進行資料/儲存網路使用
裝了8片Mellanox ConnectX-6 VPI HDR InfiniBand/200 GbE網路卡,提供叢集運算,總共具有200GB/s的尖峰效能。另有1埠雙埠ConnectX-6是用來進行資料/儲存網路使用 這就是DGX A100伺服器主機,外面還鑲金呢
這就是DGX A100伺服器主機,外面還鑲金呢 以上就是NVIDIA DGX A100世界上最先進的伺服器系統,可用來處理所有的AI工作
以上就是NVIDIA DGX A100世界上最先進的伺服器系統,可用來處理所有的AI工作 這裡是DGX A100效能簡述:INT8具備10 PetaOPS尖峰效能、FP16具備5 PetaOPS尖峰效能、TF32具備2.5 PetaOPS尖峰效能、FP64則高達156 PetaOPS尖峰效能
這裡是DGX A100效能簡述:INT8具備10 PetaOPS尖峰效能、FP16具備5 PetaOPS尖峰效能、TF32具備2.5 PetaOPS尖峰效能、FP64則高達156 PetaOPS尖峰效能 相較於高效能CPU伺服器,這台DGX A100具備150倍的AI運算效能、40倍的記憶體頻寬與I/O頻寬。現已上市,售價為199,000美元 (拾玖點玖萬美元)
相較於高效能CPU伺服器,這台DGX A100具備150倍的AI運算效能、40倍的記憶體頻寬與I/O頻寬。現已上市,售價為199,000美元 (拾玖點玖萬美元) 說到佔地面積與耗電量部分,當今AI數據中心配置50台DGX-1系統(用來做AI訓練)、600台CPU系統(用來做AI推論),總共需要耗資1千1百萬美元,佔地25櫃,耗電達630千瓦
說到佔地面積與耗電量部分,當今AI數據中心配置50台DGX-1系統(用來做AI訓練)、600台CPU系統(用來做AI推論),總共需要耗資1千1百萬美元,佔地25櫃,耗電達630千瓦 改用DGX A100之後,只要買5台就夠了!耗資僅1百萬美元,佔地僅1櫃,耗電量僅28千瓦。設備成本才1/10,電費也只有1/20!
改用DGX A100之後,只要買5台就夠了!耗資僅1百萬美元,佔地僅1櫃,耗電量僅28千瓦。設備成本才1/10,電費也只有1/20! 若以Pagerank案例來算,一般資料爬蟲應用,以2.6TB Graph – 128百萬Edge 資料量來算,就要配置3千台CPU伺服器,佔地105櫃。效能為52百萬Edges/秒
若以Pagerank案例來算,一般資料爬蟲應用,以2.6TB Graph – 128百萬Edge 資料量來算,就要配置3千台CPU伺服器,佔地105櫃。效能為52百萬Edges/秒 若改用DGX A100伺服器,只要4台即可。效能達到688百萬Edges/秒。整體效能提升13倍,成本僅1/75
若改用DGX A100伺服器,只要4台即可。效能達到688百萬Edges/秒。整體效能提升13倍,成本僅1/75此外,NVIDIA也打造700 Petaflops的次世代 DGX SuperPOD,幫助客戶在AI工作流程中運用經驗證的企業級軟體。這些SuperPOD都是配備DGX A100伺服器,以充分發揮伺服器房的坪效。
 NVIDIA也發表新的DGX A100 SuperPOD,可建置高達140台伺服器機櫃系統,數據中心要建置一列機櫃、提供高達700 PFLOPSAI效能,也只要3週即可施工完成
NVIDIA也發表新的DGX A100 SuperPOD,可建置高達140台伺服器機櫃系統,數據中心要建置一列機櫃、提供高達700 PFLOPSAI效能,也只要3週即可施工完成 未來擴充後總效能可以達到4.6 ExaFLOPS,要標下3~4件美國國家實驗室的Exascale超級電腦標案,也不是問題了XD
未來擴充後總效能可以達到4.6 ExaFLOPS,要標下3~4件美國國家實驗室的Exascale超級電腦標案,也不是問題了XD邊緣運算應用與機器人
最後,在嵌入式與邊緣AI平台方面,NVIDIA也推出EGX A100與EGX Jetson Xavier NX平台,以幫助智慧物聯、雲端AI、5G通信、車聯網、機器人等產業,建構一個雲端AI運算平台,賦予製造、零售、電信、醫療保健等產業即時的人工智慧應用。關於EGX的產品細節,可參考這裡。至於EGX Jetson Xavier NX開發套件,細節可以參考這裡。
 隆重介紹:NVIDIA EGX A100搭配Mellanox CX6 DX模組,主打邊緣AI運算
隆重介紹:NVIDIA EGX A100搭配Mellanox CX6 DX模組,主打邊緣AI運算 各部位介紹:內建一顆Ampere GPU,採用第三代Tensor Core架構,具備機密AI必要的新安全引擎、安全認證開機機制。ConnectX-6 DX網卡,提供兩埠100Gb/s的傳輸頻寬
各部位介紹:內建一顆Ampere GPU,採用第三代Tensor Core架構,具備機密AI必要的新安全引擎、安全認證開機機制。ConnectX-6 DX網卡,提供兩埠100Gb/s的傳輸頻寬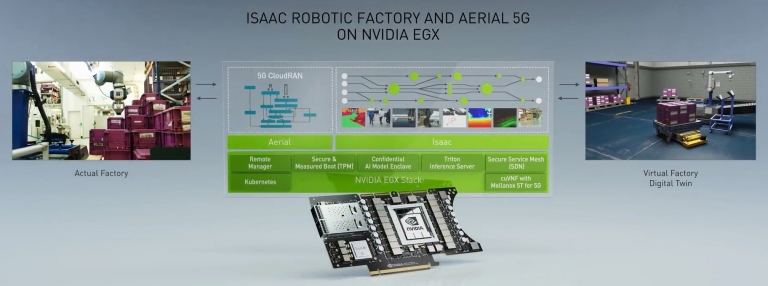 這是搭載NVIDIA EGX平台的ISSAC機器人工廠與Aerial 5G的CloudRAN(雲端無線接取網路)系統架構圖
這是搭載NVIDIA EGX平台的ISSAC機器人工廠與Aerial 5G的CloudRAN(雲端無線接取網路)系統架構圖 BMW選擇NVIDIA的ISSAC機器人平台,做為其汽車製造工廠的平台。有關於這部份的細節,可以參考這裡
BMW選擇NVIDIA的ISSAC機器人平台,做為其汽車製造工廠的平台。有關於這部份的細節,可以參考這裡 NVIDIA的EGX生態系,跨足了不同產業,此為合作夥伴列表。裡面比較熟悉的台灣廠商,就是台積電和鴻海了
NVIDIA的EGX生態系,跨足了不同產業,此為合作夥伴列表。裡面比較熟悉的台灣廠商,就是台積電和鴻海了至於在車載應用方面,NVIDIA也展示搭配新的Ampere架構GPU,將讓自駕車的等級從第2級直接跳級升到第5級,也就是無人駕駛載客等級!
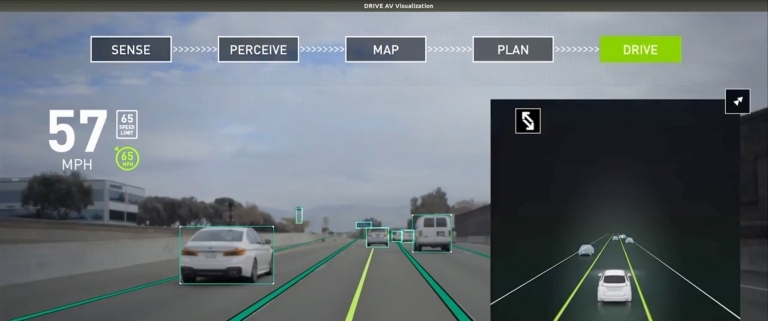 有關於NVIDIA Drive AV視覺化系統,從感測、感知到繪製、計畫,到自駕,都是環環相扣的。需要有強大的車用電腦運算能力,才能達成
有關於NVIDIA Drive AV視覺化系統,從感測、感知到繪製、計畫,到自駕,都是環環相扣的。需要有強大的車用電腦運算能力,才能達成 NVIDIA Drive車用電腦,從最早Orin架構,到最新的Ampere架構。讓最早只能做到ADAS(先進駕駛輔助系統)、先前第2級的自駕系統,到現在的第5級自駕載客車系統
NVIDIA Drive車用電腦,從最早Orin架構,到最新的Ampere架構。讓最早只能做到ADAS(先進駕駛輔助系統)、先前第2級的自駕系統,到現在的第5級自駕載客車系統 現在都流行所謂的軟體定義xx平台,而NVIDIA Drive就是軟體定義自駕平台。從資料蒐集、模型訓練、駕駛模擬,到真正上路自駕,都能一個平台全部搞定
現在都流行所謂的軟體定義xx平台,而NVIDIA Drive就是軟體定義自駕平台。從資料蒐集、模型訓練、駕駛模擬,到真正上路自駕,都能一個平台全部搞定 左為模擬駕駛的畫面,右邊為真實上路的畫面。GTC 2020也展示其已經可以順利自駕成功
左為模擬駕駛的畫面,右邊為真實上路的畫面。GTC 2020也展示其已經可以順利自駕成功 這就是NVIDIA Drive全球生態系與夥伴列表
這就是NVIDIA Drive全球生態系與夥伴列表 老黃:您的廚房有很多吃的,我的廚房有199K美元的數據中心伺服器! (設計對白/PCDIY!)
老黃:您的廚房有很多吃的,我的廚房有199K美元的數據中心伺服器! (設計對白/PCDIY!)以上就是GTC 2020的主題演講重點內容介紹,想了解更多GTC 2020主體演講細節,可移駕到NVIDIA官網。
- 發表您的看法
請勿張貼任何涉及冒名、人身攻擊、情緒謾罵、或內容涉及非法的言論。
請勿張貼任何帶有商業或宣傳、廣告用途的垃圾內容及連結。
請勿侵犯個人隱私權,將他人資料公開張貼在留言版內。
請勿重複留言(包括跨版重複留言)或發表與各文章主題無關的文章。
請勿張貼涉及未經證實或明顯傷害個人名譽或企業形象聲譽的文章。
您在留言版發表的內容需自負言論之法律責任,所有言論不代表PCDIY!雜誌立場,違反上述規定之留言,PCDIY!雜誌有權逕行刪除您的留言。
最近新增
- AMD攜手台積電,成為「TSMC Arizona」美國亞利桑那州新製造基地主要HPC客戶,啟動「2 奈米 N2 製程」打造下一代「Zen 6」研發代號「威尼斯 Venice」EPYC處理器!
- 「AMD Ryzen 9 9950X3D處理器」實測開箱,16核心32執行緒「3D V-Cache火力加持」史上最強遊戲CPU強勢來襲!
- 史上最高貴CPU來了!「台幣20萬」LGA4677戰神級56核心112執行緒Intel Xeon w9-3495X處理器正式開賣!Sapphire Rapids-WS處理器16核32緒「Xeon w5-3435X」報價55,500元、28核56緒「Xeon w7-3465X」報價100,500元、36核72緒「Xeon w9-3475X」報價128,500元「戰鬥力爆棚價格衝破天際」
- 3D V-Cache火力加持!「AMD Ryzen 7 9800X3D處理器」實測開箱,8核心16執行緒104MB快取「史上最強遊戲CPU」震撼登場!
- 「Intel合體AMD」聯手成立「x86 生態系統諮詢小組」,「加速開發人員和客戶的創新」共創美好PC產業未來!
- 「Intel Core Ultra 200S」CPU強勢來襲,史上最強「Intel第15代 研發代號 Arrow Lake」桌上型電腦處理器「台積電 TSMC 神隊友代工」LGA1851腳位「Core Ultra 5 245K/KF、Core Ultra 7 265K/KF、Core Ultra 9 285K處理器 與 Z890主機板」聯袂登場!
- AMD Ryzen Threadripper PRO 7995WX實測開箱,史上最強96核心192執行緒 採用sTR5/SP6腳位 對應TRX50、WRX90主機板 次世代 HEDT高階桌機處理器重裝上陣!
- 華碩ROG STRIX SCAR 17 X3D G733PYV效能實測,A+N最強CPU+GPU遊戲黃金組合 AMD Ryzen 9 7945HX3D配上NVIDIA GeForce RTX 4090 展現超凡入聖性能 實現絕強至猛戰鬥力!
- Intel Xeon w9-3475X實測開箱,勇猛強悍36核心72執行緒 採用LGA4677腳位 對應W790主機板 次世代 HEDT高階桌機 工作站 處理器閃耀登場!
- Intel Xeon w9-3495X實測開箱,史上最強56核心112執行緒 採用LGA4677腳位 對應W790主機板 次世代 HEDT高階桌機 工作站 處理器重裝上陣!
- 洋垃圾發威!AMD EPYC 9654殺很大,96核心192執行緒 5奈米製程 Genoa核心 384MB L3快取 價格大跳水 跌破台幣80,000元!
- AMD AI PC YES 商用電腦再升級!AI CPU三劍齊發火力全開,Ryzen Pro 8000引爆商用桌機進入AI時代,Ryzen Pro 8040加速商用筆電AI加速,Ryzen Threadripper Pro 7000WX衝破工作站極限效能!
最多人點閱
- 洋垃圾神器,Xeon E5-2670實測開箱大作戰!
- MSI CORE FROZR L CPU散熱器實測開箱,微星電競產品再添新兵
- 淘寶網洋垃圾再顯神威,1999元買到8核心16執行緒Xeon E5-2670神器級處理器!
- 捉對廝殺:AMD Ryzen 2200G/2400G VS Intel Core i3-8100/i5-8400
- 不讓Z490專美於前、Intel 400系列入門選項,BIOSTAR RACING B460GTQ主機板開箱
- 洋垃圾戰神,5999元買14核心28執行緒Xeon E5-2683v3神器級處理器!
- SUPERMICRO SUPERO M12SWA-TF伺服器主機板實測開箱,史上最強實戰AMD Ryzen Threadripper Pro 3995WX為究極效能而生!
- AMD Ryzen 5 1600X實測開箱,6核心12執行緒戰神處理器再顯鋒芒!
- 搭載USB 3.2 Gen 2x2和2.5GbE LAN、入門玩家最佳選擇,MSI MAG Z490 TOMAHAWK主機板開箱
- 太極撥10核、「十力」不容小覷,ASRock Z490 TAICHI主機板效能測試
- AMD CPU與超輕巧ITX小板輕鬆配:華碩 ROG STRIX B450-I GAMING ft. Ryzen 3 3300X
- Intel Core i5-9400F 盒裝版 正式開賣!F系列全面來襲,還會發售Core i3-9350KF、i5-9600KF、i7-9700KF、i9-9900KF處理器!

