ITMan!資訊新聞
NVIDIA Hopper 在MLPerf的生成式人工智慧領域取得飛躍性進展 業界標準測試表明,基於NVIDIA Hopper的系統運行TensorRT-LLM軟體, 為生成式AI提供了世界上最強大的平台
文.圖/張國華 2024-03-28 12:59:41
NVIDIA正式宣布在業界標準測試中提供了世界上最快的生成式人工智慧(AI)推論平台。
在最新的MLPerf基準測試中,NVIDIA TensorRT-LLM這個可加速和簡化大型語言模型的複雜推論工作的軟體將GPT-J LLM上的NVIDIA Hopper架構GPU效能較六個月前提高了近3 倍。
速度的大幅提升展示了NVIDIA的晶片、系統和軟體全端平台在滿足運行生成式AI嚴苛要求方面的強大能力。
諸多領先的公司正在使用TensorRT-LLM最佳化他們的模型。而NVIDIA NIM 是一套推論微服務,其中包含TensorRT-LLM等推論引擎,讓企業比以往能更輕鬆地部署NVIDIA推論平台。
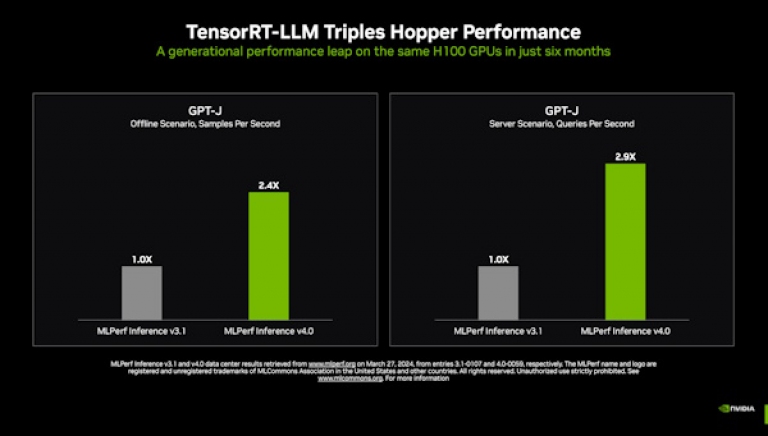
提高生成式AI的標準
在NVIDIA H200 Tensor核心GPU(最新的記憶體增強型Hopper GPU)上運行的TensorRT-LLM,在MLPerf 迄今為止最大規模的生成式 AI 測試中提供了最快的運行推論效能。新的基準測試使用Llama 2的最大版本,Llama 2是最先進的大型語言模型,包含 700 億個參數。該模型比 9 月基準測試中首次使用的GPT-J大型語言模型大 10 倍以上。
記憶體增強型H200 GPU在MLPerf首次亮相時,使用TensorRT-LLM每秒產生高達 31,000 個詞元,創下了MLPerf的Llama 2基準測試的紀錄。
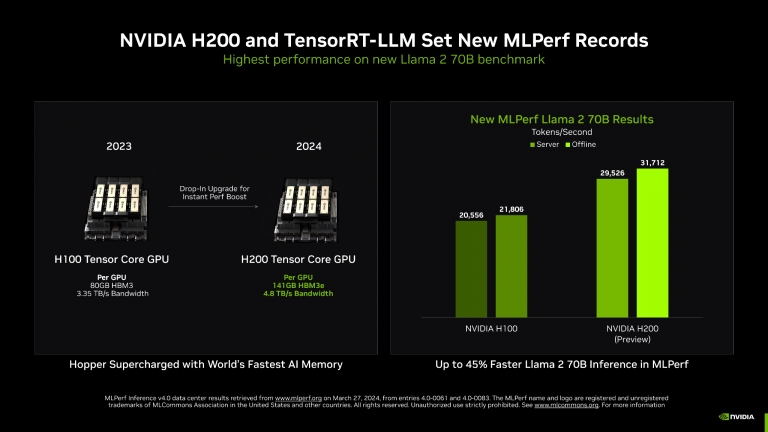
H200 GPU的結果包括客製化散熱解決方案帶來的高達14%的增益。這是標準空氣冷卻以外的創新範例之一,系統製造商正在將其應用到NVIDIA MGX設計中,以將Hopper GPU的效能提升到新的高度。
NVIDIA Hopper GPU 的記憶體提升
NVIDIA現在已提供 H200 GPU供客戶測試,並將於第二季出貨。H200 GPU很快將由近 20 家領先的系統製造商和雲端服務供應商來提供。H200 GPU包含141GB高頻寬記憶體HBM3e,運轉速度為4.8TB/s。與H100 GPU相比,記憶體增加了76%,運行速度提高了43%。這些加速器可插入與H100 GPU相同的主機板和系統,並使用相同的軟體。
借助 HBM3e 記憶體,單個H200 GPU能以最高吞吐量運行整個Llama 2 70B模型,從而簡化並加速推論。
GH200 配備更多的記憶體
NVIDIA GH200 超級晶片中配備更多記憶體,最高可達624GB高速記憶體,其中包含144GB的HBM3e記憶體,此超級晶片將Hopper 架構 GPU和節能的NVIDIA Grace CPU結合在一個模組上。NVIDIA 加速器是首批使用HBM3e記憶體技術的加速器。憑藉將近5 TB/s的記憶體頻寬,GH200超級晶片在如推薦系統等記憶體密集型的 MLPerf 測試中提供了出色的效能。
橫掃每一個 MLPerf 測試
以每個加速器為基礎,Hopper GPU 在最新一輪MLPerf產業基準測試中,橫掃了所有AI推論測試。
這些基準測試涵蓋當今最受歡迎的AI工作負載和場景,包括生成式AI、推薦系統、自然語言處理、語音和電腦視覺。NVIDIA是唯一一家在最新一輪以及自 2020 年 10 月開始 MLPerf 資料中心推論基準測試以來,每一輪都提交所有工作負載結果的公司。
持續的效能提升意味著推論成本的降低,對於全球部署的數百萬個NVIDIA GPU來說,推論已成為日常工作中的一大部分,而且還在不斷增長。
推進一切可能
NVIDIA在基準測試中一個名為「開放組」的特別部分中展示了三種創新技術,這部分是為了測試先進的AI方法而創建。NVIDIA 工程師使用了一種稱為結構化稀疏性(structured sparsity)的技術,使 Llama 2 的推論速度提高了 33%。結構化稀疏性是一種減少計算的方法,首次在 NVIDIA A100 Tensor核心GPU 中引入。
第二個開放組測試發現,使用剪枝技術(pruning)可以將推論速度提高高達40%,這是簡化AI模型(此例為大型語言模型)以增加推論吞吐量的一種方式。
最後,一種名為DeepCache的最佳化方法減少了對Stable Diffusion XL模型推論所需的數學運算,將效能提升了驚人的74%。
所有這些結果都是在NVIDIA H100 Tensor核心GPU 上運行的。
使用者值得信賴的來源
MLPerf的測試透明且客觀,因此使用者可以依靠結果做出明智的購買決定。NVIDIA的合作夥伴參與 MLPerf 是因為他們知道這對客戶評估 AI 系統和服務來說是一個很有價值的工具。
本輪在NVIDIA AI平台上提交結果的合作夥伴包括華碩電腦、思科、戴爾科技集團、富士通、技嘉科技、Google、慧與科技、聯想、Microsoft Azure、甲骨文、雲達科技、美超微、VMware(最近由博通收購)和緯穎科技。
NVIDIA在本次測試中使用的所有軟體都可以從MLPerf資源庫中取得,NVIDIA不斷將軟體最佳化結果放入NVIDIA的GPU應用軟體中心NGC以及 NVIDIA AI Enterprise的容器中。NVIDIA AI Enterprise為一個安全、受支援的平台,其中包含 NIM 推論微服務。
下一件大事
生成式AI的用例、模型大小和資料集不斷擴大。這就是MLPerf不斷發展的原因,增加了 Llama 2 70B 和 Stable Diffusion XL等主流模型的真實測試。為了跟上大型語言模型規模的爆炸性增長,NVIDIA創辦人暨執行長黃仁勳上週在GTC上宣布,NVIDIA Blackwell 架構 GPU將提供兆級參數 AI 模型所需的新效能水平。
大型語言模型的推論非常困難,需要專業知識和NVIDIA使用Hopper架構GPU和TensorRT-LLM在MLPerf上展示的全端架構。未來還會有更多。
了解有關 MLPerf 基準測試和本輪推論的技術細節。
→更多的【PCDIY!業界新聞】: 請見
→更多的【PCDIY!賣場情報】: 請見
→更多的【PCDIY!科技情報】: 請見
→更多的【IT資訊新聞】: 請見
→更多的【ITMan!資訊經理人】: 請見
→更多的【PCDIY!八卦】: 請見
延伸閱讀
(01)光華商場的新危機,淘寶網帶來的跨境電商價格戰!(02)48顆壞25顆》威騰WD RE 3TB硬碟驚爆鬧機瘟,WD3000FYYZ死機地雷硬碟故障率高到嚇人!
(03)高雄建國電腦商圈爆倒店潮,引爆網友熱議!
(04)Seagate硬碟廣告:我也不想當死雞隊友啊,引爆玩家熱議!
(05)PTT寫手門事件:電蝦板主發表不自殺聲明,引爆網友熱議!
(06)記憶體插上16GB有多爽,引爆網友熱議!
(07)英特爾Intel 10GbE網路卡X540T2,淘寶網水貨價格殺很大!
(08)SSD爆發連環關門潮,憶正Memoright驚傳財務危機疑似倒閉!
(09)幫組電腦到自己貼錢的經驗,引爆網友熱議!
(10)教授認證防毒軟體「360安全衛士」,引爆網友熱議!
(11)DDR4記憶體金手指歪掉惹,引爆網友熱議!
(12)原價屋的商業模式,引爆網友熱議!
(13)Intel CPU神保固,舊換新大升級引爆網友狂推聯強貨!
(14)日本寬頻網路10G光纖上網,引爆網友熱議!
(15)Windows XP再戰十年,引爆網友熱議!
(16)光華商場的下一步,全世界都在看!
(17)東芝TOSHIBA Harrier MG03ACA300 3TB企業級硬碟,中國水貨價格殺很大!
(18)洋垃圾神器,Xeon E5-2670實測開箱大作戰!
(19)硬碟故障資料救援,等了一年八個月...
(20)新一代玩家聖物,6700元買16核心32執行緒Xeon E5-2675 v3處理器!
(21)淘寶網洋垃圾再顯神威,1999元買到8核心16執行緒Xeon E5-2670神器級處理器!
(22)洋垃圾戰神,5999元買14核心28執行緒Xeon E5-2683v3神器級處理器!
(23)硬碟用SSD有多爽,引爆網友熱議!
(24)磁碟陣列要選RAID 5還是RAID 6 引爆網友熱議!
(25)電腦CPU沒三萬沒法玩這遊戲,引爆網友熱議!
(26)為什麼有人要推AMD CPU菜單,引爆網友熱議!
(27)200TB資料怎麼儲存,引爆網友熱議!
(28)硬碟故障資料救援報價3萬8 引爆網友熱議!
(29)NVIDIA顯示卡的品牌怎麼挑選 引爆網友熱議!
(30)高科技竹筷,對付笨重顯示卡的神兵利器!
(31)電腦機殼價格破萬 引爆網友熱議!
(32)be quiet!電源供應器爆假貨,引爆了鍵盤大戰!





















- 發表您的看法
請勿張貼任何涉及冒名、人身攻擊、情緒謾罵、或內容涉及非法的言論。
請勿張貼任何帶有商業或宣傳、廣告用途的垃圾內容及連結。
請勿侵犯個人隱私權,將他人資料公開張貼在留言版內。
請勿重複留言(包括跨版重複留言)或發表與各文章主題無關的文章。
請勿張貼涉及未經證實或明顯傷害個人名譽或企業形象聲譽的文章。
您在留言版發表的內容需自負言論之法律責任,所有言論不代表PCDIY!雜誌立場,違反上述規定之留言,PCDIY!雜誌有權逕行刪除您的留言。
最近新增
- LG MoodMate 小暮光全新風格登場,打破投影機框架 追劇 × 音樂 × 光影氛圍一機整合,重塑居家投影的想像
- 征服荒漠極境!ASUS ProArt GoPro Edition 筆電攜手Red Bull運動員翱翔創作天際
- 威剛25周年迎雙囍!連續七年摘下亞洲企業社會責任獎 董事長陳立白獲頒「負責任企業領袖獎」
- 《神之塔:New World》在三週年更新前推出[奧佩拉的主人]雷普爾雷斯塔
- 日本Good Smile Company迎接25週年計畫! 原創新作機器人動畫《合體神系列》啟動!
- 日本加速全固態電池研發、供應鏈建立,國家補助金額已達6.6億美元
- NVIDIA 發佈能為代理加速科學探索的工具 BioNeMo Agent Toolkit
- HPE將自駕網路擴展至邊緣、園區、資料中心與AI工廠
- 技鋼科技攜 AI、HPC 與次世代基礎架構亮相 ISC High Performance 2026 全面展出橫跨 NVIDIA、AMD 與 Intel 平台的端對端解決方案,涵蓋加速運算、科學研究與企業 AI 應用
- 華星光電IJP OLED將於2026下半年導入品牌監視器及筆電產品,韓系主導格局迎來挑戰
- 微軟推出專為效能與靈活性設計的全新 Surface Pro 與 Surface Laptop
- XPG 擴大散熱產品佈局!MAESTRO 風冷與 INFINITY 風扇系列全新上市 賦予玩家無限改裝創意 輕鬆升級極致效能與美學
最多人點閱
- 2024開學季筆電選購指南: 10大熱銷筆電推薦榜
- 超車Intel最強Xeon Platinum 8380處理器2.8倍性能!AMD第四代EPYC 9004系列正式登場,引進12通道DDR5-4800記憶體、PCIe 5.0、CXL記憶體與最高96核心192執行緒戰鬥力,霄龍EPYC 9654榮登伺服器處理器世界之王!
- 散熱頂天!「華碩 GeForce RTX 50 全系列顯示卡」勁勢登場,「ROG、TUF Gaming、Prime」系列5070、5070 Ti、5080與5090顯示卡接力上市!
- Synology 推出全新機種「DS925+、DS1525+ 與 DS1825+」,2025 年式 NAS 為高效且可靠的資料管理需求而設計
- 「振華 SUPER FLOWER」推出雙白金、全模組、專利九宮格任意插全新世代「LEADEX VII Platinum PRO ATX 3.1電源供應器」,給你自由擴充的未來!
- 英特爾推出全新Xeon W-2400、W-3400工作站處理器-專業人士的絕佳解決方案!
- 王者堆料!技嘉科技發表「GeForce RTX 50系列顯示卡」,正式發售「AORUS系列XTREME WATERFORCE、MASTER與GIGABYTE系列GAMING,AERO、WINDFORCE」系列GeForce RTX 5080、5090顯示卡!
- 戴爾簡化 AI PC 時代的周邊設備管理 全新四款 Dell Pro 擴充基座搭配強大管理工具助力效能提升
- TP-Link台灣針對市場引導性報導回應:「TP-Link台灣所販售的產品均符合當地相關法律規範及資安要求。我們將持續秉持高標準,履行在安全與創新方面的承諾,為全球用戶提供值得信賴的網路解決方案!」
- TrendForce:「2023年全球DRAM記憶體模組」市場整體營收達125億美元,「Kingston 金士頓」以68.8%的市占率穩居龍頭,「POWEV 嘉合勁威」以5.6%的市占率排名第二,「ADATA 威剛」以4.5%的市占率排名第三,「Kimtigo 金泰克」以4.2%的市占率排名第四,「Ramaxel 記憶科技」以3.7%的市占率排名第五!
- 「凱斯克 Kiss Quiet」推出 超高性價比 電源供應器!不到千元級距「Kiss Quiet Elite II 500W 」回饋愛用者,採用日系電容 搶攻裝機升級市場 上市特價:990元!80 PLUS 銅牌認證「Kiss Quiet Mega-B II 」推廣電腦組裝用戶,採用日系電容 靜音風扇 550W 上市特價:1,490元 650W 上市特價:1,690元!德國匠人精神,嚴格把關品質!
- 「凱斯克 Kiss Quiet SILENT G3 全模組化 80 PLUS 金牌認證 650W、750W、850W、1050W 電源供應器」上市!內外兼具「ATX 3.1最新規格、PCI SIG CEM 5.1顯卡電源、H++ 90度接頭、日系電容、全模接頭、強固纜繩、智慧停轉、送理線夾、高性價比、十一年保」PC DIY組裝電腦 黑白雙色電源 優質選擇!

