PCDIY!業界新聞
雲端服務供應商與伺服器製造商運用 NVIDIA AI 提升 AI 訓練標準,戴爾科技、浪潮、Microsoft Azure 與美超微於今日公布的最新 MLPerf 基準測試,刷新訓練 AI 模型速度的紀錄
(本資訊由廠商提供,不代表PCDIY!立場) 2021-12-02 15:44:01
眾家企業刷新訓練人工智慧 (AI) 模型速度的紀錄,包括戴爾科技 (Dell Technologies)、浪潮 (Inspur)、美超微 (Supermicro),以及首度在 MLPerf 基準測試中亮相的 Azure,均採用 NVIDIA AI。
我們的平台在今日公布的 MLPerf 訓練 1.1 結果中,創下所有八項熱門作業負載中的紀錄。
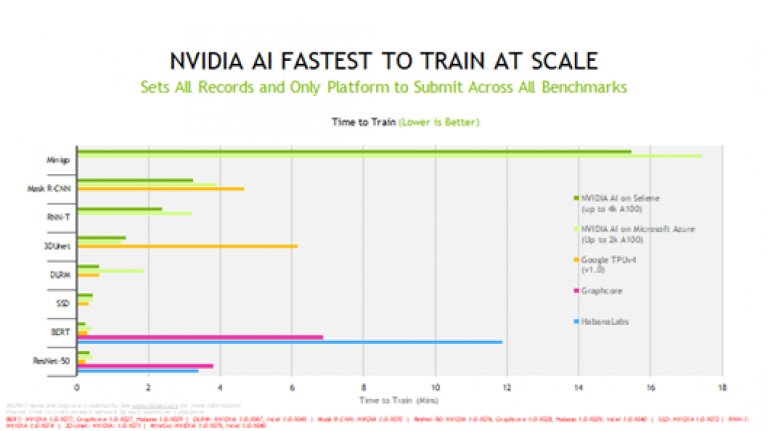 圖一_根據最新的測試結果,NVIDIA AI 訓練所有模型的速度均取得領先
圖一_根據最新的測試結果,NVIDIA AI 訓練所有模型的速度均取得領先NVIDIA A100 Tensor 核心 GPU 不僅提供最佳的標準化單晶片效能,並透過 NVIDIA InfiniBand 連網技術及軟體堆疊進行擴充,在 Selene 系統上提供最快的訓練時間。Selene 是 NVIDIA 基於模組化 NVIDIA DGX SuperPOD 的 AI 超級電腦。
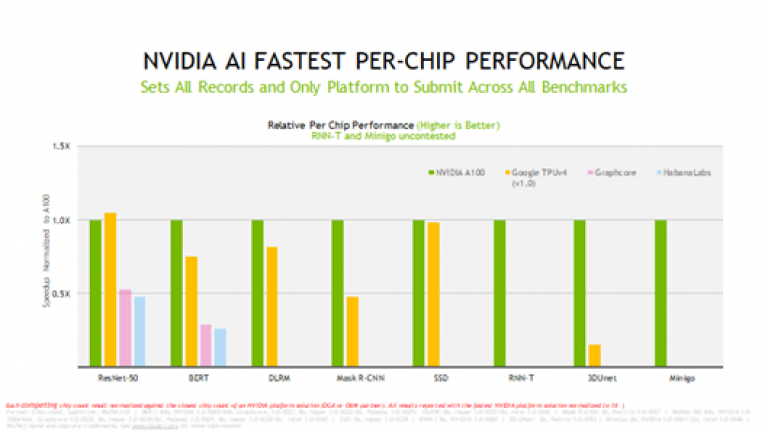 圖二_NVIDIA A100 GPU 在所有八項 MLPerf 1.1 測試中均提供最佳的單晶片訓練效能
圖二_NVIDIA A100 GPU 在所有八項 MLPerf 1.1 測試中均提供最佳的單晶片訓練效能邁向巔峰的雲端
根據最新公布的結果,在訓練 AI 模型方面,Azure 的 NDm A100 v4 是當今全球最快的執行個體。其在最新一輪完成每一項測試,並能擴充至 2,048 個 A100 GPU。Azure 不僅展現絕佳的效能,現在更於全美六個地區供任何人租用與使用。
AI 訓練是一項艱鉅的任務,因此需要強大的軟硬體支援。我們希望用戶能運用其所挑選的服務或系統,在破紀錄的速度下完成模型訓練。因此,我們透過 NVIDIA AI 為雲端服務、託管服務,以及企業與科學運算中心提供產品支援。
伺服器製造商展現強大的實力
在 OEM 廠商中,浪潮運用其 8 路 GPU 系統,包含 NF5488A5 與液體冷卻 NF5688MB,刷新最多單節點效能紀錄。戴爾科技與美超微則憑藉搭載 4 路 A100 GPU 的系統刷新紀錄。此次共有十家 NVIDIA 合作夥伴提交測試結果,包含八家 OEM 廠商及兩家雲端服務供應商,其所提交的件數占總數 90% 以上。
這是第五輪的效能測試,也是至今 NVIDIA 商業生態系在 MLPerf 效能訓練基準測試中表現最為亮眼的一次。
我們的合作夥伴積極參與這項測試,因 MLPerf 是唯一業界標準且經同業審核的 AI 訓練與推論基準,其為客戶評估 AI 平台和廠商的寶貴工具。
速度經過認證的伺服器
百度 Paddle Paddle、戴爾科技、富士通 (Fujitsu)、技嘉 (GIGABYTE)、慧與科技 (Hewlett Packard Enterprise;HPE)、浪潮、聯想 (Lenovo) 以及美超微皆提交於單節點和多節點的本地端資料中心測試結果。幾乎所有我們的 OEM 合作夥伴皆在 NVIDIA 認證系統上執行效能測試,我們為需要加速運算的企業客戶進行伺服器驗證。
各方提交的結果展現出 NVIDIA 平台應用的廣度與成熟度,並且能為任何規模的企業提供最佳的解決方案。
既快速又具彈性的系統
NVIDIA AI 是唯一提交數據於所有測試項目與使用案例的平台參與者,充份展現 NVIDIA AI 的多元性及絕佳效能。既快速又具彈性的系統,提供客戶加快作業速度所需的生產力。訓練基準測試涵蓋當今最熱門的八項 AI 作業負載與情境,包括電腦視覺、自然語言處理、推薦系統,以及強化學習等。
MLPerf 的測試透明且客觀,因此用戶可以依據結果做出採購決策。此業界基準測試小組成立於 2018 年 5 月,並取得數十家業界領導廠商的全力支持,包括阿里巴巴 (Alibaba)、安謀 (Arm)、Google、英特爾 (Intel),以及 NVIDIA 等。
三年內速度提升 20 倍
過往的測試數據顯示我們的 A100 GPU 於過去 18 個月內效能提升 5 倍。這都要歸功於持續創新的軟體,而這也是我們近期著重發展的領域。自三年前 MLPerf 測試推出以來,NVIDIA 的效能提升超過 20 倍。如此可觀的加速反映出我們在 GPU、網路、系統,以及軟體的全端產品中取得的進步。
MLPerf training 20x improvements over three years
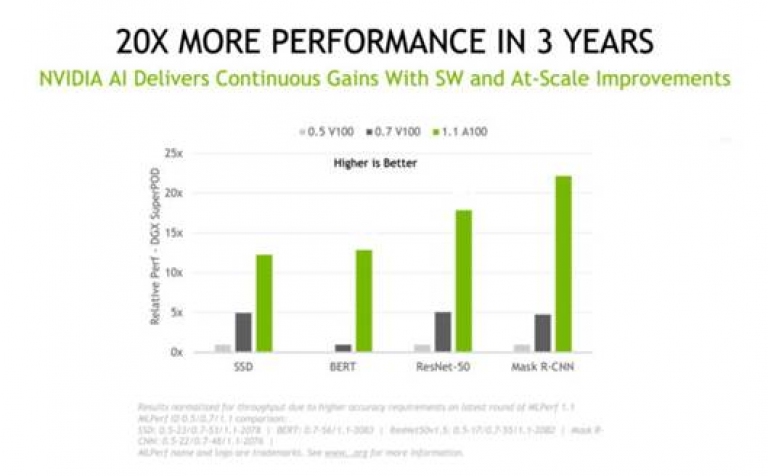 圖三_NVIDIA AI 在過去三年內,效能提升超過 20 倍
圖三_NVIDIA AI 在過去三年內,效能提升超過 20 倍持續優化的軟體
我們的最新進展來自多方面的軟體優化。例如採用全新類別記憶體複製模式,讓我們在醫學成像的 3D-Unet 基準測試中創下2.5 倍的速度提升。藉由針對平行處理校正 GPU 的方法,我們在物體偵測的 Mask R-CNN 測試中獲得 10% 的速度提升,並在推薦系統中獲得 27% 的提升。我們將這些重複運用在各項獨立測試,而在涉及多 GPU 運算作業時尤其能反映出加速成效。
我們擴大 CUDA 繪圖的運用以盡可能縮短與主機 CPU 的傳輸時間,使得在影像分類的 ResNet-50 項目中獲得 6% 的效能提升。
此外,我們亦在 NCCL 執行兩項全新技術,其為最佳化 GPU 間傳輸作業的函式庫,讓 BERT 等大型語言模型獲得 5% 的效能提升。
運用我們努力的成果
我們使用的所有軟體皆能透過 MLPerf 資料庫取得,因此所有人都能取得我們世界級的研發成果。我們持續將這些最佳化結果整合至我們的 GPU 應用程式軟體中心 NGC 上的各項容器。這些成果是全端平台的一部分,於最新發表的業界基準測試取得認證,並可透過各領域的合作夥伴取得,以處理當今的 AI 作業。
- 發表您的看法
請勿張貼任何涉及冒名、人身攻擊、情緒謾罵、或內容涉及非法的言論。
請勿張貼任何帶有商業或宣傳、廣告用途的垃圾內容及連結。
請勿侵犯個人隱私權,將他人資料公開張貼在留言版內。
請勿重複留言(包括跨版重複留言)或發表與各文章主題無關的文章。
請勿張貼涉及未經證實或明顯傷害個人名譽或企業形象聲譽的文章。
您在留言版發表的內容需自負言論之法律責任,所有言論不代表PCDIY!雜誌立場,違反上述規定之留言,PCDIY!雜誌有權逕行刪除您的留言。
最近新增
- TrendAI加入Anthropic Project Glasswing 雙方合作運用先進AI能力,加速軟體漏洞的發掘與修補能力
- EDIFIER 全新 M90 2.0 藍牙喇叭解鎖全方位「聲」活體驗 讓好聲音不受空間限制 聽歌到追劇全面升級!隨時切換電視、手機、電腦多種娛樂模式 限時預購享 95 折優惠
- COMPUTEX 2026圓滿落幕!串聯全球創新能量 共創AI生態新格局
- ZOTAC於COMPUTEX 2026慶祝成立20週年 發佈品牌全線AI產品願景
- MSI攜手NVIDIA於COMPUTEX 2026發表首款搭載NVIDIA RTX Spark筆記型電腦
- Synology 於 COMPUTEX 2026 揭曉新世代 DiskStation Manager 與全方位資料管理解決方案
- 芝奇於Computex 2026展示全新DDR5 Trident Z5 NeoX RGB系列 支援AMD EXPO Technology: Featuring Ultra Low Latency
- 技嘉擴大 AI TOP 生態系版圖,迎接 AI Agent 新時代
- JONSBO 喬思伯全線新品搶先看:極致光影與鋁合金工藝的火花盛宴
- 技嘉於 COMPUTEX 2026 展出獲國際大獎肯定 AI 電競筆電陣容 GiMATE 全新進化升級遊戲與創作體驗
- 技嘉「ENTER NFINITY」席捲 COMPUTEX 2026,大秀 PC創新、AI運算與電競體驗頂尖實力
- 技嘉於 COMPUTEX 2026 發表 AORUS K10 INFINITY 電競鍵盤與 M10 INFINITY 電競滑鼠
最多人點閱
- SP廣穎電通將於德國2015 Embedded World展示全方位工控系列產品
- InWin 805 NVIDIA EDITION機殼爆紅,迎廣GeForce GTX特仕版機箱正式開賣!
- 2024開學季筆電選購指南: 10大熱銷筆電推薦榜
- Windows 10 搭載 Office 版本聲明稿 Office Mobile 、 Office 2016 與 Office 365 版本差異說明
- 你的人生「升級」了沒?倒數十天!Windows 10開闊你的無限視野
- 全新Intel Core X系列處理器- Intel Core i9 極致版處理器 重裝上陣
- PLEXTOR展現軟實力,一舉推出三大獨家軟體
- JEDEC發布全新DDR5標準規範,從DDR5-4800起跳! 將加速導入下世代高效能電腦系統
- 不再是Toshiba品牌,全新Dynabook 2019 新品發布,透過運算與服務改變世界
- Mac 版 Office 2016 正式在台上市!
- microSD技術邁入第十年,SanDisk microSD記憶卡出貨量突破20億片
- 英特爾前進3D NAND,發表Intel SSD 600p、6000p、E 5420s、E 6000p、DC P3520、DC S3520固態硬碟!

