CPU / 中央處理器
美國Aurora國家實驗室Exascale超級電腦配備揭曉,採用Intel Xe HPC ‘PVC’ GPU與Xeon Sapphire Rapids CPU,2021年開始部署 ft. 兩大CPU市場分析
文.圖/Johan 2020-05-11 13:00:00
這篇不是超級英雄之戰,而是超級電腦之戰!上週我們報導過Intel確認將推出Xe HP 萬能級GPU,採用MCM封裝,該GPU核心就是Ponte Vecchio (義大利佛羅倫斯市內的一座老橋),採用7nm製程設計,裡面電容數超過數以十億計,大小為3696mm²,寬度比一顆AA電池還大!令人大開眼界!
由於先前Intel標到Aurora超級電腦建構計畫,其合作內容是,Intel將與Cray一同建構起Exascale (百億億次級) 超級電腦,並於2021年部署!這次的超級電腦將採用兩組Sapphire Rapids Xeon處理器,以及高達6顆上述的Ponte Vecchio GPU,這些GPU將採用CXL (Compute Express Link)與OneAPI軟體堆疊來進行連接,以達到高效能運算目標。
 Intel標到的Aurora超級電腦建構計畫中,將採用的電腦主機架構。採用雙Xeon可擴充處理器,搭配6顆Xe架構Ponte Vecchio繪圖處理器,採用UMA(統一記憶體架構)、全節點互連設計,具可擴充能力之節點間異步化I/O處理
Intel標到的Aurora超級電腦建構計畫中,將採用的電腦主機架構。採用雙Xeon可擴充處理器,搭配6顆Xe架構Ponte Vecchio繪圖處理器,採用UMA(統一記憶體架構)、全節點互連設計,具可擴充能力之節點間異步化I/O處理
Intel的Aurora超級電腦標案,將採用的電腦硬體,細節說明
這款電腦由於配置了6顆PVC Xe HPC (7nm) GPU和2顆Sapphire Rapids Xeon CPU (10nm++) CPU,在各GPU之間將採用CXL (Compute Express Link)與OneAPI軟體堆疊來進行連接,系統採用統一記憶體架構(UMA)讓CPU和GPU的資料可以共用存取,以達到高效能運算目標。
Intel的Aurora超級電腦標案,其使用的節點與互連機制架構說明
Intel GPU的內部架構說明
Cray的Shasta系統說明
而在記憶體、儲存裝置與頻寬部份,先說記憶體好了,他們表示正在尋找能配置超過10 PB (1 PB = 1024TB)的系統記憶體,搭配Cray的Slingshot Fabric互連機制。已知Aurora超級電腦的每個運算節點,總共有8個Slingshot Fabric進行互連,而該電腦系統也會採用兩種不同的檔案系統,其中一個是DAOS (分佈式異步對象儲存),另一個則是Lustre。兩者各有其優點,一個是高容量低頻寬,另一個則是相反,分述如下:
(1) DAOS: 可支援大約 230 PB的儲存容量,頻寬超過25TB/s
(2) Lustre: 可完整支援到150 PB 的儲存容量,頻寬大約1 TB/s
Cray的Slingshot網路架構說明
此外,在軟體方面,Cray也有自己的軟體堆疊層,可改善模組效率,同時提供統一的高效能互連機制。有鑑於其Slingshot是其第八代高速互連架構,具備許多HPC應用的必備特色,像是壅塞管理、僅3 hops的dragonfly系統,還有流量類別。同時還使用Rosetta高頻寬交換器,能提供高達25.6Tb/s的頻寬(單一方向為25GB/s),以符合Exascale等級的運算需求。
Cray的Dragonfly拓樸說明
Cray的Rosetta高頻寬交換器介紹
DAOS (分佈式異步對象儲存)架構說明
這就是Aurora的硬體特色一覽表
Xe Link,將這6顆粒GPU連接在一起,以CXL為基礎
Xe GPU的三個等級,從高至低依序是:Xe HPC、Xe HP、Xe LP
Xe GPU 三種等級的效能區間分佈圖
Xe GPU 區分的市場等級,從最高階數據中心,到消費端的繪圖加速
由於Intel的Xe HPC GPU,將具有幾千個EU (執行單元),目前已知Xe LP GPU有96組EU,每個EU共有8個核心,因此相乘起來共有768組GPU核心。目前Intel在Gen 9.5和Gen 11的GPU上,每個切片上面擁有8組EU,同時包含8組ALU (算術邏輯單元),而在Gen12 GPU的子切片中,其EU裡面有點像是NVIDIA在GPC裡面的Shader Model (SM)單元,或是AMD在Shader Engine裡面的CU (運算單元)的組成。因此這樣演化下去,將可以看到大量由許多子切片所組成的超級切片。
這就是Intel DG1 (採用Xe LP GPU)顯示卡本尊與產品特色
簡單來說,1顆具備1000個EU的GPU晶片,裡面就含有8000組GPU核心,不過有可能更多,因為先前有看到中階的Xe HP GPU以4顆堆起的大GPU,就內建了2048個EU (相當於16384組GPU核心)的設計,預期高階的Xe HPC GPU將可能更多,晶圓面積也將更巨大!
這是Intel Xe HPC GPU (Ponte Vecchio) 7nm GPU的內部架構,一個切片有8個EU
由於Xe HP GPU具備可變動向量寬度指令集,例如GPU專用的SIMT,以及CPU專用的SIMD格式,兩者搭配起來將有最大效能。而根據Xe HP GPU的單顆、雙顆、四顆搭起來之後,其效能大概可以預估如下:
(1) Intel Xe HP (12.5) 1顆GPU: 512 EU (約4096核心,12.2 TFLOPs,150W)
(2) Intel Xe HP (12.5) 2顆GPU: 1024 EU (約8192核心,20.48 TFLOPs,300W)
(3) Intel Xe HP (12.5) 4顆GPU: 2048 EU (約16384 核心,36 TFLOPs,400~500W)
這就是Intel Xe HP GPU (Ponte Vecchio)的MCM封裝,好大一顆!
此外,Xe HPC還包含一個Rambo Cache,是一個超大型的快取架構,負責將多顆GPU串連在一起。此外透過該快取的巨大級記憶體頻寬,可以持續性的在雙精度運算中,提供尖峰的FP64運算效能。這樣在進行密集的AI運算時,能夠快速且有效的完成各式工作。
Xe HPC採用UMA架構,每個EU以XEMF串起,連接至HBM記憶體,並搭配Rambo Cache設計,以讓GPU和CPU共同存取
至於在製程方面,因為10nm升級到7nm,所以在GPU裡面也獲得一些關鍵性的提升,包含:7nm製程擁有10nm的兩倍密度、Die內部節點優化、設計準則減少4倍、採用EUV (極紫外)光刻機製程、採用下世代Foveros與EMIB封裝。
Xe HPC採用7nm製程設計,以及Foveros封裝技術
這次Xe HPC GPU的推出,搭配OneAPI軟體架構,將使其單一節點的效能,相較於2019年來說,提升超過500倍,2021年見真章!
有GPU不夠,也要看CPU,這次Aurora超級電腦,搭配的是Xeon等級之CPU,具備ECC記憶體校正等功能
說到這次新的Eagle Stream平台,將採用全新LGA 4677腳位,以取代先前Whitley的LGA 4189腳位(支援Cooper Lake-SP與Ice Lake-SP處理器)。(是的!腳位一直改!)
Sapphire Rapids Xeon處理器,將採用Willow Cove架構!
若跟AMD相比,AMD將於2021年推出EPYC “Milan”伺服器處理器,採用7nm Zen 3架構、支援PCIe 4.0與DDR4。而要是Intel不Delay的話,其2021年推出的Sapphire Rapids Xeon CPU雖說採用10nm++製程,且支援PCIe 5.0與DDR5,記憶體將支援到8通道,雖說製程落後(10nm++),但規格上卻領先,將可能又把AMD的Milan往下踩。也因此,AMD可能要加緊推出其EPYC “Genoa”,採用新的SP5腳位設計,將以5nm製程設計,支援DDR5與PCIe 5.0等新規格,來與Intel正面對戰!
AMD在伺服器處理器市場部分,於2021年祭出EPYC “Milan”,是基於Zen 3架構、7nm製程的處理器
各家超級電腦標案的電腦系統名稱、交付日期,與CPU+GPU供應廠商名單
至於比較具有可看性的Exascale超級電腦標案中,除了上述Intel標到的Aurora標案之外,AMD也有標到Frontier超級電腦建構計畫,由是AMD負責CPU與GPU的建構,Cray負責系統、機櫃與互連。在同樣建構Exascale超級電腦的計畫中,AMD表示將採用最新的EPYC 7000處理器,搭配自家Radeon Instinct GPU,來組成1.5百億億次級以上(1.5 exaFLOPs)尖峰處理能力的超級電腦,以用來處理天氣、亞原子結構、基因組學、物理學等科學進行模擬、建立模型等應用。這個案子的CPU和GPU都是AMD自己包辦!
除此之外,HPE (慧宇)也於今年3月標到El Capitan超級電腦建構計畫,將與AMD合作(為什麼不選Intel? 耐人尋味!),共同打造2百億億次級以上(2 exaFLOPs)尖峰處理能力的超級電腦,並預定於2023年初部署,以提供美國國家核子安全總署(NNSA,National Nuclear Security Administration)使用,該超級電腦將主要用在核子武器建模 (疑? 不是拿來做COVID-19研究喔?!)。
超級電腦中,GPU的效能成為主要重點,這是各家GPU的內部架構!
從上述的Exascale超級電腦標案中,可看出AMD與HPE合作一起拿下的Frontier與El Capitan兩個標案,分別為1.5或2 exaFLOPS等級的超級電腦標案,相較於Intel拿到的Aurora標案僅 1 exaFLOPS,看來AMD陣營還是略勝一籌!只是2021年之後就都要交出成績單了,屆時就要看哪一家在Super Computing的效能競賽中獲得優勝了!誰能成為Super Computing業界中的SuperHero,目前還不曉得。只能說,2021年的伺服器市場戰役,將會非常精彩!
由於先前Intel標到Aurora超級電腦建構計畫,其合作內容是,Intel將與Cray一同建構起Exascale (百億億次級) 超級電腦,並於2021年部署!這次的超級電腦將採用兩組Sapphire Rapids Xeon處理器,以及高達6顆上述的Ponte Vecchio GPU,這些GPU將採用CXL (Compute Express Link)與OneAPI軟體堆疊來進行連接,以達到高效能運算目標。
 Intel標到的Aurora超級電腦建構計畫中,將採用的電腦主機架構。採用雙Xeon可擴充處理器,搭配6顆Xe架構Ponte Vecchio繪圖處理器,採用UMA(統一記憶體架構)、全節點互連設計,具可擴充能力之節點間異步化I/O處理
Intel標到的Aurora超級電腦建構計畫中,將採用的電腦主機架構。採用雙Xeon可擴充處理器,搭配6顆Xe架構Ponte Vecchio繪圖處理器,採用UMA(統一記憶體架構)、全節點互連設計,具可擴充能力之節點間異步化I/O處理Aurora國家實驗室公佈硬體細節,採2 CPU + 6 GPU設計
由Intel主導的Aurora超級電腦建構計畫,已於日前公布其細節,該電腦將配備上述的2顆Sapphire Rapids Xeon CPU,以及6顆Ponte Vecchio (PVC)的Xe HPC等級GPU,預計將達到1 ExaFLOPs的巔峰效能,該系統將在2021年正式於Argonne國家實驗室部署,此將成為地表上首台Exascale級的超級電腦!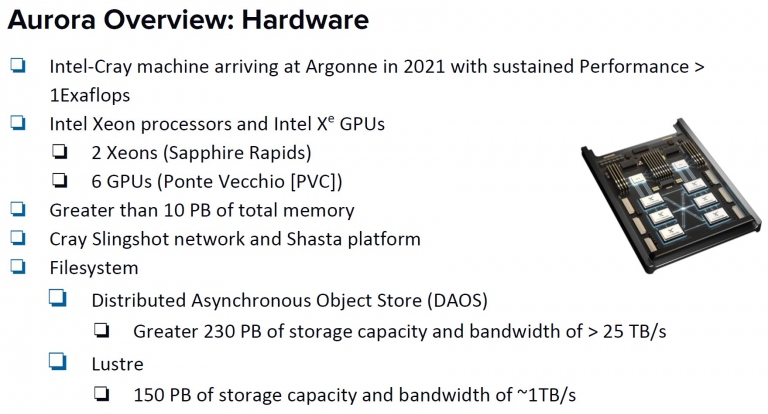 Intel的Aurora超級電腦標案,將採用的電腦硬體,細節說明
Intel的Aurora超級電腦標案,將採用的電腦硬體,細節說明這款電腦由於配置了6顆PVC Xe HPC (7nm) GPU和2顆Sapphire Rapids Xeon CPU (10nm++) CPU,在各GPU之間將採用CXL (Compute Express Link)與OneAPI軟體堆疊來進行連接,系統採用統一記憶體架構(UMA)讓CPU和GPU的資料可以共用存取,以達到高效能運算目標。
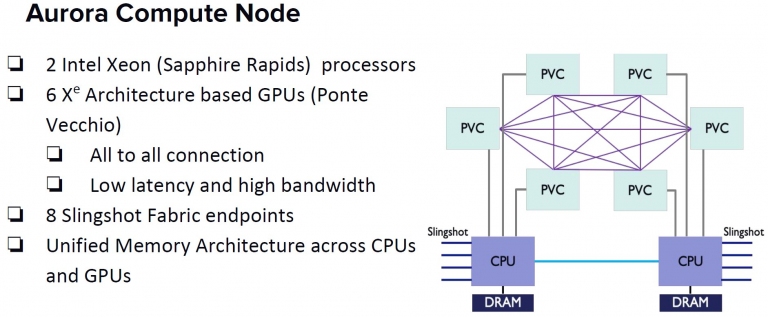 Intel的Aurora超級電腦標案,其使用的節點與互連機制架構說明
Intel的Aurora超級電腦標案,其使用的節點與互連機制架構說明 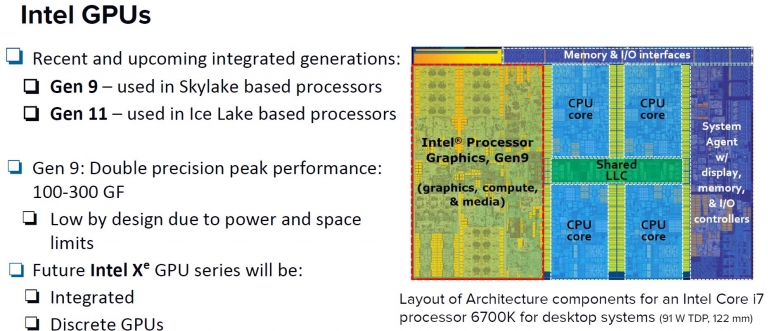 Intel GPU的內部架構說明
Intel GPU的內部架構說明 Cray負責機架與系統設計,以串起高效能應用需求
這項計畫中,Intel主要負責做CPU與GPU,而Cray (克雷電腦)則負責設計載體,也就是他們Shasta系統,其包含機架與機櫃,該機架支持各種CPU,並能針對伺服器密度、散熱效率,以及高效能網路頻寬進行不同比例的優化 (Cray可說是這次計畫的SI廠商),讓Intel這個全新的處理器架構,能夠在高效能運算(HPC)應用中,穩定運作且發揮出全速效能。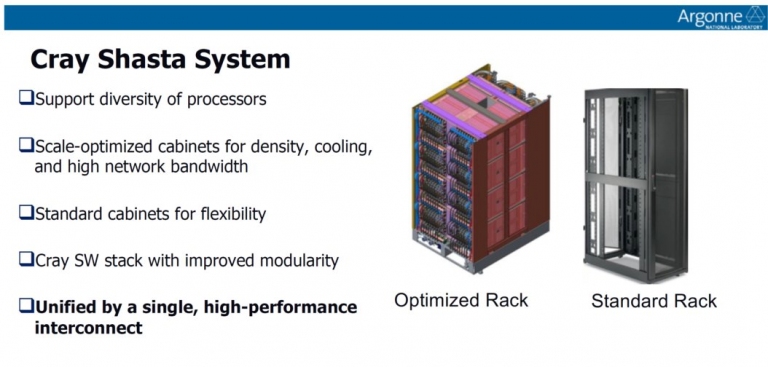 Cray的Shasta系統說明
Cray的Shasta系統說明而在記憶體、儲存裝置與頻寬部份,先說記憶體好了,他們表示正在尋找能配置超過10 PB (1 PB = 1024TB)的系統記憶體,搭配Cray的Slingshot Fabric互連機制。已知Aurora超級電腦的每個運算節點,總共有8個Slingshot Fabric進行互連,而該電腦系統也會採用兩種不同的檔案系統,其中一個是DAOS (分佈式異步對象儲存),另一個則是Lustre。兩者各有其優點,一個是高容量低頻寬,另一個則是相反,分述如下:
(1) DAOS: 可支援大約 230 PB的儲存容量,頻寬超過25TB/s
(2) Lustre: 可完整支援到150 PB 的儲存容量,頻寬大約1 TB/s
 Cray的Slingshot網路架構說明
Cray的Slingshot網路架構說明此外,在軟體方面,Cray也有自己的軟體堆疊層,可改善模組效率,同時提供統一的高效能互連機制。有鑑於其Slingshot是其第八代高速互連架構,具備許多HPC應用的必備特色,像是壅塞管理、僅3 hops的dragonfly系統,還有流量類別。同時還使用Rosetta高頻寬交換器,能提供高達25.6Tb/s的頻寬(單一方向為25GB/s),以符合Exascale等級的運算需求。
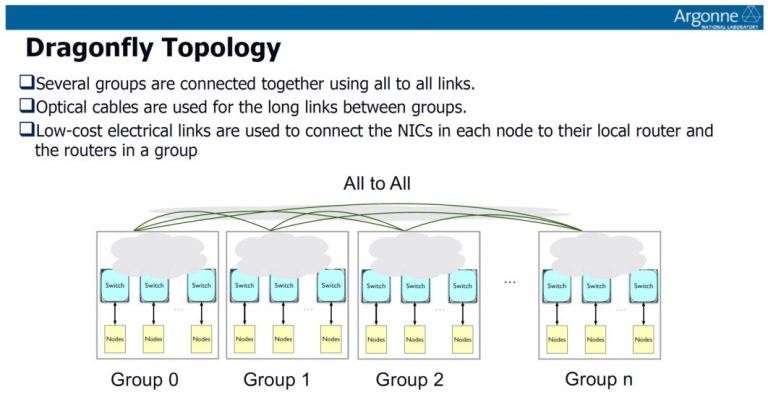 Cray的Dragonfly拓樸說明
Cray的Dragonfly拓樸說明 Cray的Rosetta高頻寬交換器介紹
Cray的Rosetta高頻寬交換器介紹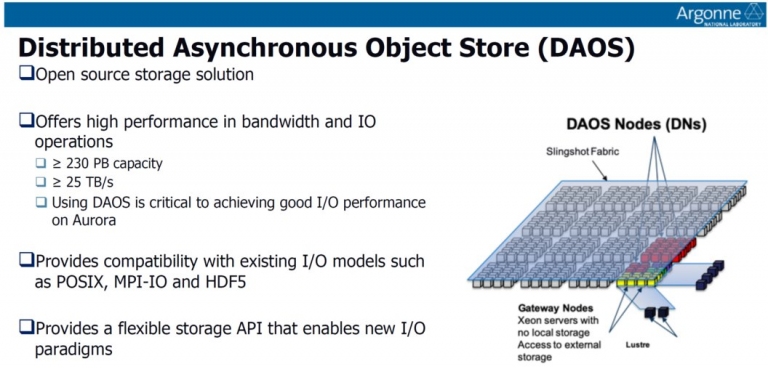 DAOS (分佈式異步對象儲存)架構說明
DAOS (分佈式異步對象儲存)架構說明 這就是Aurora的硬體特色一覽表
這就是Aurora的硬體特色一覽表Intel的10nm++ CPU配7nm GPU強嗎?Xe GPU架構分析
Intel Xe家族,依照等級高低可區分成最高階的HPC、中階的HP,以及消費性的LP。先說最高檔的HPC吧!這次的Ponte Vecchio (PVC) GPU,將採用7nm製程設計,搭配其Foveros 3D封裝技術,並以MCM的封裝設計,晶圓面積勢必不小。此外,每顆MCM GPU將通過EMIB (嵌入式多晶片互連橋接,Embedded Multi-die Interconnect Bridge)連接到高密度HBM(高頻寬記憶體)之DRAM封裝,並在旁邊放置一個更快速的Rambo Cache,該快取也是透過Foveros來進行連接。再搭配Cray的Slingshot提供節點之間的互連,便可透過Intel Xe Link將6顆Xe HPC GPU內部互連起來! Xe Link,將這6顆粒GPU連接在一起,以CXL為基礎
Xe Link,將這6顆粒GPU連接在一起,以CXL為基礎 Xe GPU的三個等級,從高至低依序是:Xe HPC、Xe HP、Xe LP
Xe GPU的三個等級,從高至低依序是:Xe HPC、Xe HP、Xe LP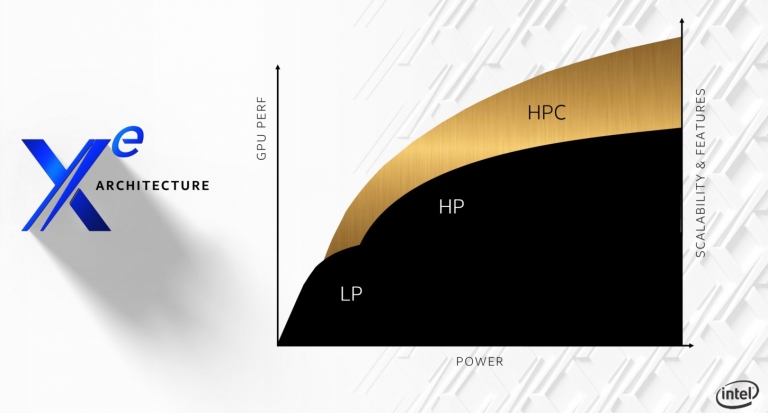 Xe GPU 三種等級的效能區間分佈圖
Xe GPU 三種等級的效能區間分佈圖 Xe GPU 區分的市場等級,從最高階數據中心,到消費端的繪圖加速
Xe GPU 區分的市場等級,從最高階數據中心,到消費端的繪圖加速由於Intel的Xe HPC GPU,將具有幾千個EU (執行單元),目前已知Xe LP GPU有96組EU,每個EU共有8個核心,因此相乘起來共有768組GPU核心。目前Intel在Gen 9.5和Gen 11的GPU上,每個切片上面擁有8組EU,同時包含8組ALU (算術邏輯單元),而在Gen12 GPU的子切片中,其EU裡面有點像是NVIDIA在GPC裡面的Shader Model (SM)單元,或是AMD在Shader Engine裡面的CU (運算單元)的組成。因此這樣演化下去,將可以看到大量由許多子切片所組成的超級切片。
 這就是Intel DG1 (採用Xe LP GPU)顯示卡本尊與產品特色
這就是Intel DG1 (採用Xe LP GPU)顯示卡本尊與產品特色簡單來說,1顆具備1000個EU的GPU晶片,裡面就含有8000組GPU核心,不過有可能更多,因為先前有看到中階的Xe HP GPU以4顆堆起的大GPU,就內建了2048個EU (相當於16384組GPU核心)的設計,預期高階的Xe HPC GPU將可能更多,晶圓面積也將更巨大!
 這是Intel Xe HPC GPU (Ponte Vecchio) 7nm GPU的內部架構,一個切片有8個EU
這是Intel Xe HPC GPU (Ponte Vecchio) 7nm GPU的內部架構,一個切片有8個EU由於Xe HP GPU具備可變動向量寬度指令集,例如GPU專用的SIMT,以及CPU專用的SIMD格式,兩者搭配起來將有最大效能。而根據Xe HP GPU的單顆、雙顆、四顆搭起來之後,其效能大概可以預估如下:
(1) Intel Xe HP (12.5) 1顆GPU: 512 EU (約4096核心,12.2 TFLOPs,150W)
(2) Intel Xe HP (12.5) 2顆GPU: 1024 EU (約8192核心,20.48 TFLOPs,300W)
(3) Intel Xe HP (12.5) 4顆GPU: 2048 EU (約16384 核心,36 TFLOPs,400~500W)
 這就是Intel Xe HP GPU (Ponte Vecchio)的MCM封裝,好大一顆!
這就是Intel Xe HP GPU (Ponte Vecchio)的MCM封裝,好大一顆!Xe HPC GPU之間巨無霸級的快取,肩負FP64等級的運算需求
至於高階的Xe HPC GPU,Raja Koduri在Intel開發者大會提到,HPC將可達到1000個EU,相當於單顆就有8000個GPU核心,且提供40倍的雙精度浮點運算能力。其中,每個EU是透過新的可擴充式記憶體fabric架構來串連起來,這個新的互連架構就叫做XEMF (即Xe Memory Fabric),可提供數組高頻寬的記憶體通道。跟Xeon CPU一樣,Xe HPC GPU也需要配置具備ECC功能的記憶體來運作。此外,Xe HPC還包含一個Rambo Cache,是一個超大型的快取架構,負責將多顆GPU串連在一起。此外透過該快取的巨大級記憶體頻寬,可以持續性的在雙精度運算中,提供尖峰的FP64運算效能。這樣在進行密集的AI運算時,能夠快速且有效的完成各式工作。
 Xe HPC採用UMA架構,每個EU以XEMF串起,連接至HBM記憶體,並搭配Rambo Cache設計,以讓GPU和CPU共同存取
Xe HPC採用UMA架構,每個EU以XEMF串起,連接至HBM記憶體,並搭配Rambo Cache設計,以讓GPU和CPU共同存取至於在製程方面,因為10nm升級到7nm,所以在GPU裡面也獲得一些關鍵性的提升,包含:7nm製程擁有10nm的兩倍密度、Die內部節點優化、設計準則減少4倍、採用EUV (極紫外)光刻機製程、採用下世代Foveros與EMIB封裝。
 Xe HPC採用7nm製程設計,以及Foveros封裝技術
Xe HPC採用7nm製程設計,以及Foveros封裝技術 這次Xe HPC GPU的推出,搭配OneAPI軟體架構,將使其單一節點的效能,相較於2019年來說,提升超過500倍,2021年見真章!
這次Xe HPC GPU的推出,搭配OneAPI軟體架構,將使其單一節點的效能,相較於2019年來說,提升超過500倍,2021年見真章!那麼Sapphire Rapids Xeon CPU的功能又是如何?
在伺服器處理器方面,Intel這次推出的Sapphire Raids Xeon伺服器處理器,將採用10nm++製程,將可能採用Willow Cove核心架構,以取代先前的Sunny Cove架構。此外,這次的Sapphire Raids Xeon處理器,搭配其最新的Eagle Stream晶片組平台,將首度支援到DDR5記憶體,以及PCIe 5.0架構 (對!直接跳到5.0了,不跟你AMD的4.0喇賽)。 有GPU不夠,也要看CPU,這次Aurora超級電腦,搭配的是Xeon等級之CPU,具備ECC記憶體校正等功能
有GPU不夠,也要看CPU,這次Aurora超級電腦,搭配的是Xeon等級之CPU,具備ECC記憶體校正等功能說到這次新的Eagle Stream平台,將採用全新LGA 4677腳位,以取代先前Whitley的LGA 4189腳位(支援Cooper Lake-SP與Ice Lake-SP處理器)。(是的!腳位一直改!)
 Sapphire Rapids Xeon處理器,將採用Willow Cove架構!
Sapphire Rapids Xeon處理器,將採用Willow Cove架構!若跟AMD相比,AMD將於2021年推出EPYC “Milan”伺服器處理器,採用7nm Zen 3架構、支援PCIe 4.0與DDR4。而要是Intel不Delay的話,其2021年推出的Sapphire Rapids Xeon CPU雖說採用10nm++製程,且支援PCIe 5.0與DDR5,記憶體將支援到8通道,雖說製程落後(10nm++),但規格上卻領先,將可能又把AMD的Milan往下踩。也因此,AMD可能要加緊推出其EPYC “Genoa”,採用新的SP5腳位設計,將以5nm製程設計,支援DDR5與PCIe 5.0等新規格,來與Intel正面對戰!
 AMD在伺服器處理器市場部分,於2021年祭出EPYC “Milan”,是基於Zen 3架構、7nm製程的處理器
AMD在伺服器處理器市場部分,於2021年祭出EPYC “Milan”,是基於Zen 3架構、7nm製程的處理器全面對戰!Intel和AMD從入門市場打到超級電腦市場
上述只的是Intel於2021年必須交付的Aurora exascale系統。當然其實除了Intel之外,還有許多超級電腦標案,包括先前2018年IBM與NVIDIA合作的Summit與Sierra標案,分別擁有200與125 petaflops尖峰處理能力。而2020年AMD與NVIDIA即將交付的Perlmutter超級電腦,則採用上述Zen 3架構EPYC “Milan”處理器與NVIDIA的Tesla GPU,預期可以達到100 petaflops的處理能力,但這些案子都是屬於Pre-exascale等級的超級電腦標案。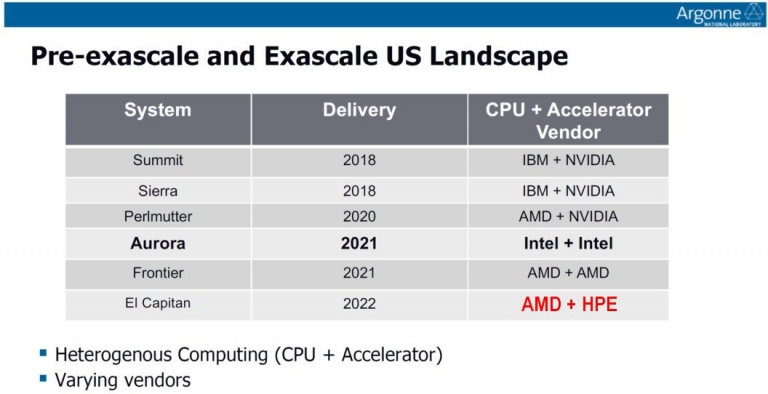 各家超級電腦標案的電腦系統名稱、交付日期,與CPU+GPU供應廠商名單
各家超級電腦標案的電腦系統名稱、交付日期,與CPU+GPU供應廠商名單至於比較具有可看性的Exascale超級電腦標案中,除了上述Intel標到的Aurora標案之外,AMD也有標到Frontier超級電腦建構計畫,由是AMD負責CPU與GPU的建構,Cray負責系統、機櫃與互連。在同樣建構Exascale超級電腦的計畫中,AMD表示將採用最新的EPYC 7000處理器,搭配自家Radeon Instinct GPU,來組成1.5百億億次級以上(1.5 exaFLOPs)尖峰處理能力的超級電腦,以用來處理天氣、亞原子結構、基因組學、物理學等科學進行模擬、建立模型等應用。這個案子的CPU和GPU都是AMD自己包辦!
除此之外,HPE (慧宇)也於今年3月標到El Capitan超級電腦建構計畫,將與AMD合作(為什麼不選Intel? 耐人尋味!),共同打造2百億億次級以上(2 exaFLOPs)尖峰處理能力的超級電腦,並預定於2023年初部署,以提供美國國家核子安全總署(NNSA,National Nuclear Security Administration)使用,該超級電腦將主要用在核子武器建模 (疑? 不是拿來做COVID-19研究喔?!)。
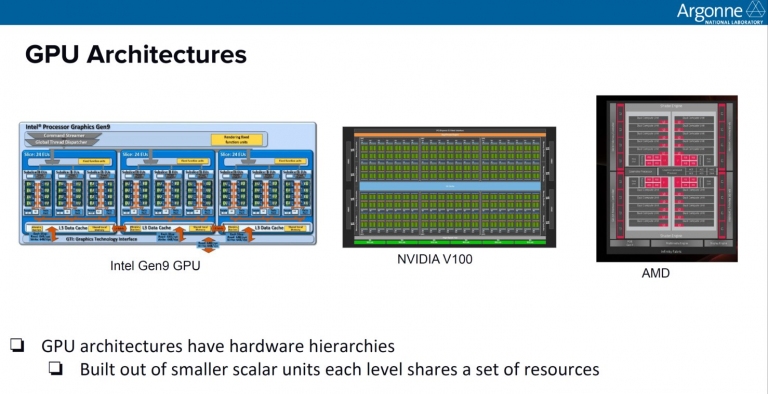 超級電腦中,GPU的效能成為主要重點,這是各家GPU的內部架構!
超級電腦中,GPU的效能成為主要重點,這是各家GPU的內部架構! 從上述的Exascale超級電腦標案中,可看出AMD與HPE合作一起拿下的Frontier與El Capitan兩個標案,分別為1.5或2 exaFLOPS等級的超級電腦標案,相較於Intel拿到的Aurora標案僅 1 exaFLOPS,看來AMD陣營還是略勝一籌!只是2021年之後就都要交出成績單了,屆時就要看哪一家在Super Computing的效能競賽中獲得優勝了!誰能成為Super Computing業界中的SuperHero,目前還不曉得。只能說,2021年的伺服器市場戰役,將會非常精彩!
- 發表您的看法
請勿張貼任何涉及冒名、人身攻擊、情緒謾罵、或內容涉及非法的言論。
請勿張貼任何帶有商業或宣傳、廣告用途的垃圾內容及連結。
請勿侵犯個人隱私權,將他人資料公開張貼在留言版內。
請勿重複留言(包括跨版重複留言)或發表與各文章主題無關的文章。
請勿張貼涉及未經證實或明顯傷害個人名譽或企業形象聲譽的文章。
您在留言版發表的內容需自負言論之法律責任,所有言論不代表PCDIY!雜誌立場,違反上述規定之留言,PCDIY!雜誌有權逕行刪除您的留言。
最近新增
- AMD攜手台積電,成為「TSMC Arizona」美國亞利桑那州新製造基地主要HPC客戶,啟動「2 奈米 N2 製程」打造下一代「Zen 6」研發代號「威尼斯 Venice」EPYC處理器!
- 「AMD Ryzen 9 9950X3D處理器」實測開箱,16核心32執行緒「3D V-Cache火力加持」史上最強遊戲CPU強勢來襲!
- 史上最高貴CPU來了!「台幣20萬」LGA4677戰神級56核心112執行緒Intel Xeon w9-3495X處理器正式開賣!Sapphire Rapids-WS處理器16核32緒「Xeon w5-3435X」報價55,500元、28核56緒「Xeon w7-3465X」報價100,500元、36核72緒「Xeon w9-3475X」報價128,500元「戰鬥力爆棚價格衝破天際」
- 3D V-Cache火力加持!「AMD Ryzen 7 9800X3D處理器」實測開箱,8核心16執行緒104MB快取「史上最強遊戲CPU」震撼登場!
- 「Intel合體AMD」聯手成立「x86 生態系統諮詢小組」,「加速開發人員和客戶的創新」共創美好PC產業未來!
- 「Intel Core Ultra 200S」CPU強勢來襲,史上最強「Intel第15代 研發代號 Arrow Lake」桌上型電腦處理器「台積電 TSMC 神隊友代工」LGA1851腳位「Core Ultra 5 245K/KF、Core Ultra 7 265K/KF、Core Ultra 9 285K處理器 與 Z890主機板」聯袂登場!
- AMD Ryzen Threadripper PRO 7995WX實測開箱,史上最強96核心192執行緒 採用sTR5/SP6腳位 對應TRX50、WRX90主機板 次世代 HEDT高階桌機處理器重裝上陣!
- 華碩ROG STRIX SCAR 17 X3D G733PYV效能實測,A+N最強CPU+GPU遊戲黃金組合 AMD Ryzen 9 7945HX3D配上NVIDIA GeForce RTX 4090 展現超凡入聖性能 實現絕強至猛戰鬥力!
- Intel Xeon w9-3475X實測開箱,勇猛強悍36核心72執行緒 採用LGA4677腳位 對應W790主機板 次世代 HEDT高階桌機 工作站 處理器閃耀登場!
- Intel Xeon w9-3495X實測開箱,史上最強56核心112執行緒 採用LGA4677腳位 對應W790主機板 次世代 HEDT高階桌機 工作站 處理器重裝上陣!
- 洋垃圾發威!AMD EPYC 9654殺很大,96核心192執行緒 5奈米製程 Genoa核心 384MB L3快取 價格大跳水 跌破台幣80,000元!
- AMD AI PC YES 商用電腦再升級!AI CPU三劍齊發火力全開,Ryzen Pro 8000引爆商用桌機進入AI時代,Ryzen Pro 8040加速商用筆電AI加速,Ryzen Threadripper Pro 7000WX衝破工作站極限效能!
最多人點閱
- 洋垃圾神器,Xeon E5-2670實測開箱大作戰!
- MSI CORE FROZR L CPU散熱器實測開箱,微星電競產品再添新兵
- 淘寶網洋垃圾再顯神威,1999元買到8核心16執行緒Xeon E5-2670神器級處理器!
- 捉對廝殺:AMD Ryzen 2200G/2400G VS Intel Core i3-8100/i5-8400
- 不讓Z490專美於前、Intel 400系列入門選項,BIOSTAR RACING B460GTQ主機板開箱
- 洋垃圾戰神,5999元買14核心28執行緒Xeon E5-2683v3神器級處理器!
- SUPERMICRO SUPERO M12SWA-TF伺服器主機板實測開箱,史上最強實戰AMD Ryzen Threadripper Pro 3995WX為究極效能而生!
- AMD Ryzen 5 1600X實測開箱,6核心12執行緒戰神處理器再顯鋒芒!
- 搭載USB 3.2 Gen 2x2和2.5GbE LAN、入門玩家最佳選擇,MSI MAG Z490 TOMAHAWK主機板開箱
- 太極撥10核、「十力」不容小覷,ASRock Z490 TAICHI主機板效能測試
- AMD CPU與超輕巧ITX小板輕鬆配:華碩 ROG STRIX B450-I GAMING ft. Ryzen 3 3300X
- Intel Core i5-9400F 盒裝版 正式開賣!F系列全面來襲,還會發售Core i3-9350KF、i5-9600KF、i7-9700KF、i9-9900KF處理器!

