PCDIY!業界新聞
NVIDIA 打破八項人工智慧效能紀錄
(本資訊由廠商提供,不代表PCDIY!立場) 2019-07-16 10:45:01
從八小時到八十秒:NVIDIA 大幅縮短訓練人工智慧的時間,NVIDIA為唯一在六個類別裡皆表現卓越的公司
這就是為什麼想要在人工智慧領域坐穩領導地位,先得在人工智慧基礎設施取得領先地位,而這也正解釋了日前發佈的 MLPerf 人工智慧訓練成果會如此重要的原因。
NVIDIA 達成 MLPerf 六項基準測試的耀眼成績,展現出世界級的卓越效能表現和多功能性。NVIDIA 的人工智慧平台在訓練效能方面創下八項記錄,其中包括三項大規模整體效能紀錄及五項基於每個加速器的效能紀錄。
 表1:NVIDIA MLPerf 人工智慧紀錄
表1:NVIDIA MLPerf 人工智慧紀錄
每個加速器的比較結果取自於先前提出之單一 NVIDIA DGX-2H (16個 V100 GPU) 與其它同規模相比較的 MLPerf 0.6 的效能 (除 MiniGo 採用的是搭載8個 V100 GPU 的 NVIDIA DGX-1) 最大規模 | MLPerf ID Max Scale: Mask R-CNN: 0.6-23,GNMT: 0.6-26,MiniGo: 0.6-11 | 每個加速器 MLPerf ID: Mask R-CNN,SSD,GNMT,Transformer:皆使用 0.6-20,MiniGo: 0.6-10
Google、Intel、百度、NVIDIA及創造 MLPerf 人工智慧基準測試套件的數十間頂尖科技公司和大學支持著這些測試結果數據,並將其轉化為具有重要創新意義的內容。
簡單來說,過去要花上一整個工作天才能完成訓練的人工智慧模型,NVIDIA 的人工智慧平台如今只要不到兩分鐘的時間便能完成。
企業明白要釋放這種生產力才是致勝關鍵。超級電腦現在儼然成為人工智慧領域的重要工具,而想要在人工智慧領域站上領導地位,需要有強大人工智慧運算基礎設施的支持。
我們最新的 MLPerf 測試結果充分展現出將 NVIDIA V100 Tensor Core GPU 用在超級運算等級基礎設施所能帶來的優點。
2017年春季,搭載 V100 GPU 的 NVIDIA DGX-1 系統花了一整個工作天,也就是八個小時來訓練影像辨識模型 ResNet-50。
如今同樣搭載 V100 GPU 的 NVIDIA DGX SuperPOD 與 Mellanox InfiniBand 進行串連,再使用經 NVIDIA 優化後用於分散式人工智慧訓練的最新人工智慧軟體,只用了 80 秒便完成了訓練影像辨識模型 ResNet-50 任務。這比煮一杯咖啡的時間還要短。
AI 的時光機,2019 MLPerf ID (圖中從上到下):ResNet-50: 0.6-30 | Transformer: 0.6-28 | GNMT: 0.6-14 | SSD: 0.6-27 | MiniGo: 0.6-11 | Mask R-CNN: 0.6-23
DGX SuperPOD 打破大規模人工智慧紀錄 大規模 MLPerf 0.6 效能 | 大規模 MLPerf ID: RN50 v1.5: 0.6-30, 0.6-6 | Transformer: 0.6-28, 0.6-6 | GNM: 0.6-26,0.6-5 | SSD: 0.6-27,0.6-6 | MiniGo: 0.6-11,0.6-7 | Mask R-CNN: 0.6-23,0.6-3
更進一步觀察便會發現,在大重量物體偵測及強化學習這兩項最困難的人工智慧問題上,NVIDIA 人工智慧平台於總訓練時間方面脫穎而出。
使用 Mask R-CNN 深度神經網路進行大重量物體偵測,可為使用者提供進階的實例分割。其用途包括將其與攝影機、感應器、超音波等多個資料來源搭配使用,以精確辨識並對特定物體進行定位。
這類人工智慧工作負載有助於訓練自動駕駛車,對行人及其它物體進行精確定位。另一個實際用途,便是協助醫師在醫療掃描影像中找尋和辨識腫瘤,其意義非凡。
NVIDIA 花不到 19 分鐘便完成了大重量物體偵測測試,效能幾乎是第二名的兩倍。
強化學習同屬不易處理的高難度類別,這種人工智慧方法可以用於訓練工廠車間的機器人,以簡化生產流程;在市區也能用它來控制紅綠燈,以舒緩塞車情況。NVIDIA 使用 NVIDIA DGX SuperPOD,在破紀錄的 13.57 分鐘內便完成對 MiniGo AI 強化訓練模型的訓練。
使用者可以從 NGC 容器 registry 免費下載已完成優化的 CUDA-X AI 軟體,對 DGX SuperPOD 進行全面設定,便能立即享受到領先全球的人工智慧效能。
NVIDIA 與生態系中超過130萬名的 CUDA 開發者合作,致力於支援各種人工智慧框架及開發環境。
我們已經協助優化了數百萬行程式碼,無論是在雲端、資料中心或是網路邊緣,只要在能找到 NVIDIA GPU 的地方,我們的客戶便能夠部署其人工智慧專案。
拜 CUDA-X AI 軟體堆疊的創新內容所賜,NVIDIA DGX-2H 伺服器的 MLPerf 0.6 處理量較我們七個月前發佈的結果提升了 80%。
與同一時期單一 DGX-2H 伺服器的處理量相比,同一伺服器的效能提升達 80% (資料集單次通過神經網路) | MLPerf ID 0.5/0.6 比較:ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20
這些成果加總起來,背後代表著數百億美元的投資和心力,這一切都是為了讓你能夠在今日快速完成工作,以及未來在更短的時間內完成工作。
如果你動作不夠快,就無法成為第一。
全球頂尖企業的研究人員和資料科學家團隊,都致力於創造需要被訓練且更複雜的人工智慧模型,而且他們動作還得快。這就是為什麼想要在人工智慧領域坐穩領導地位,先得在人工智慧基礎設施取得領先地位,而這也正解釋了日前發佈的 MLPerf 人工智慧訓練成果會如此重要的原因。
NVIDIA 達成 MLPerf 六項基準測試的耀眼成績,展現出世界級的卓越效能表現和多功能性。NVIDIA 的人工智慧平台在訓練效能方面創下八項記錄,其中包括三項大規模整體效能紀錄及五項基於每個加速器的效能紀錄。
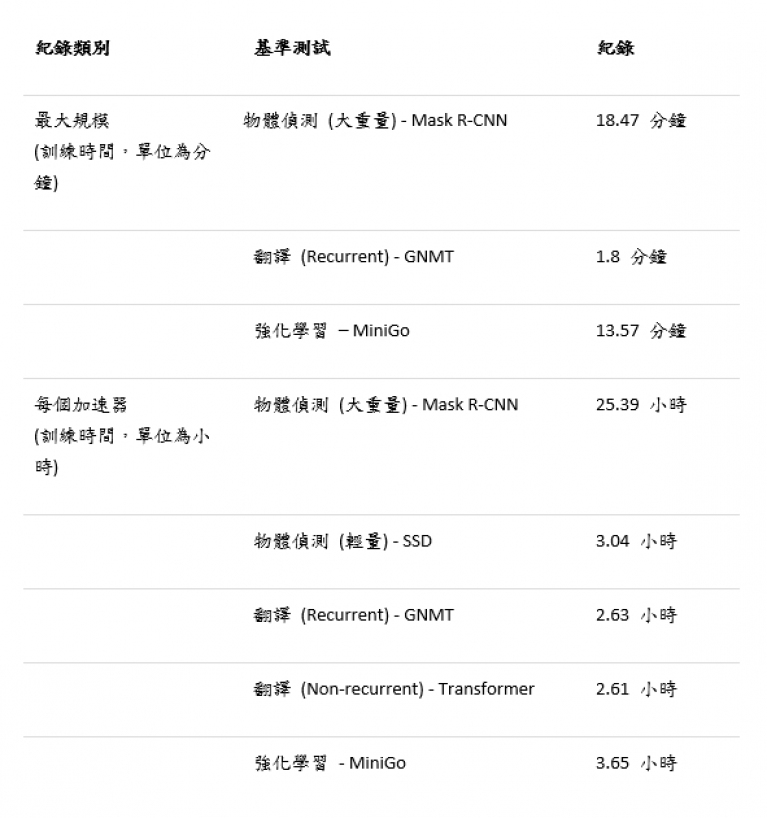 表1:NVIDIA MLPerf 人工智慧紀錄
表1:NVIDIA MLPerf 人工智慧紀錄每個加速器的比較結果取自於先前提出之單一 NVIDIA DGX-2H (16個 V100 GPU) 與其它同規模相比較的 MLPerf 0.6 的效能 (除 MiniGo 採用的是搭載8個 V100 GPU 的 NVIDIA DGX-1) 最大規模 | MLPerf ID Max Scale: Mask R-CNN: 0.6-23,GNMT: 0.6-26,MiniGo: 0.6-11 | 每個加速器 MLPerf ID: Mask R-CNN,SSD,GNMT,Transformer:皆使用 0.6-20,MiniGo: 0.6-10
Google、Intel、百度、NVIDIA及創造 MLPerf 人工智慧基準測試套件的數十間頂尖科技公司和大學支持著這些測試結果數據,並將其轉化為具有重要創新意義的內容。
簡單來說,過去要花上一整個工作天才能完成訓練的人工智慧模型,NVIDIA 的人工智慧平台如今只要不到兩分鐘的時間便能完成。
企業明白要釋放這種生產力才是致勝關鍵。超級電腦現在儼然成為人工智慧領域的重要工具,而想要在人工智慧領域站上領導地位,需要有強大人工智慧運算基礎設施的支持。
我們最新的 MLPerf 測試結果充分展現出將 NVIDIA V100 Tensor Core GPU 用在超級運算等級基礎設施所能帶來的優點。
2017年春季,搭載 V100 GPU 的 NVIDIA DGX-1 系統花了一整個工作天,也就是八個小時來訓練影像辨識模型 ResNet-50。
如今同樣搭載 V100 GPU 的 NVIDIA DGX SuperPOD 與 Mellanox InfiniBand 進行串連,再使用經 NVIDIA 優化後用於分散式人工智慧訓練的最新人工智慧軟體,只用了 80 秒便完成了訓練影像辨識模型 ResNet-50 任務。這比煮一杯咖啡的時間還要短。
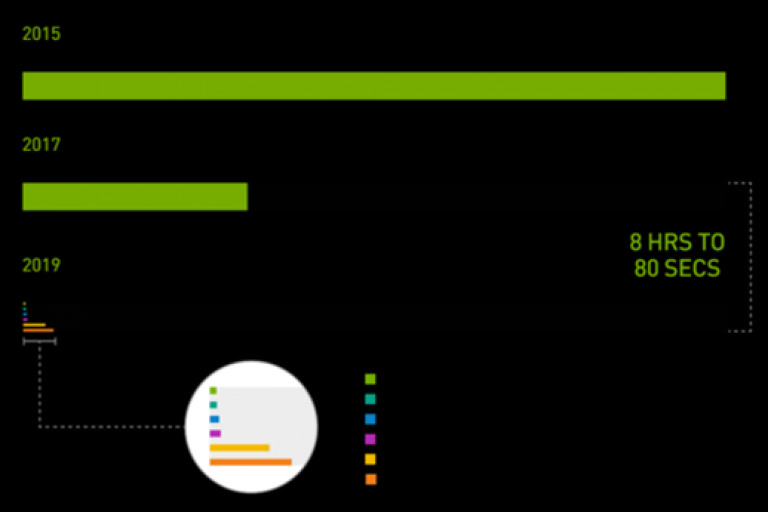 AI 的時光機,2019 MLPerf ID (圖中從上到下):ResNet-50: 0.6-30 | Transformer: 0.6-28 | GNMT: 0.6-14 | SSD: 0.6-27 | MiniGo: 0.6-11 | Mask R-CNN: 0.6-23
AI 的時光機,2019 MLPerf ID (圖中從上到下):ResNet-50: 0.6-30 | Transformer: 0.6-28 | GNMT: 0.6-14 | SSD: 0.6-27 | MiniGo: 0.6-11 | Mask R-CNN: 0.6-23人工智慧的基本工具:DGX SuperPOD 可以更快完成工作負載
仔細觀看今日的 MLPerf 結果,顯示出 NVIDIA DGX SuperPOD 是唯一一個以不到 20分鐘便完成 MLPerf 六項測試的人工智慧平台: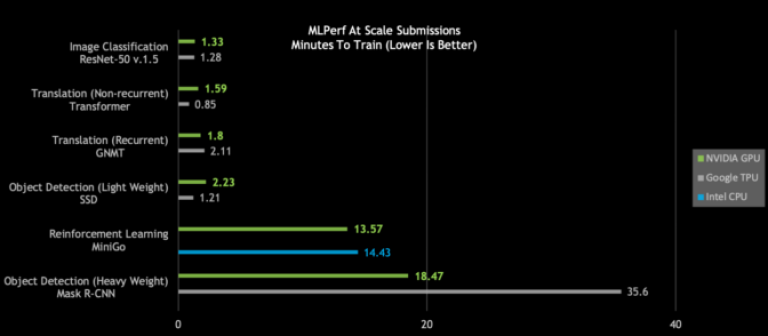 DGX SuperPOD 打破大規模人工智慧紀錄 大規模 MLPerf 0.6 效能 | 大規模 MLPerf ID: RN50 v1.5: 0.6-30, 0.6-6 | Transformer: 0.6-28, 0.6-6 | GNM: 0.6-26,0.6-5 | SSD: 0.6-27,0.6-6 | MiniGo: 0.6-11,0.6-7 | Mask R-CNN: 0.6-23,0.6-3
DGX SuperPOD 打破大規模人工智慧紀錄 大規模 MLPerf 0.6 效能 | 大規模 MLPerf ID: RN50 v1.5: 0.6-30, 0.6-6 | Transformer: 0.6-28, 0.6-6 | GNM: 0.6-26,0.6-5 | SSD: 0.6-27,0.6-6 | MiniGo: 0.6-11,0.6-7 | Mask R-CNN: 0.6-23,0.6-3更進一步觀察便會發現,在大重量物體偵測及強化學習這兩項最困難的人工智慧問題上,NVIDIA 人工智慧平台於總訓練時間方面脫穎而出。
使用 Mask R-CNN 深度神經網路進行大重量物體偵測,可為使用者提供進階的實例分割。其用途包括將其與攝影機、感應器、超音波等多個資料來源搭配使用,以精確辨識並對特定物體進行定位。
這類人工智慧工作負載有助於訓練自動駕駛車,對行人及其它物體進行精確定位。另一個實際用途,便是協助醫師在醫療掃描影像中找尋和辨識腫瘤,其意義非凡。
NVIDIA 花不到 19 分鐘便完成了大重量物體偵測測試,效能幾乎是第二名的兩倍。
強化學習同屬不易處理的高難度類別,這種人工智慧方法可以用於訓練工廠車間的機器人,以簡化生產流程;在市區也能用它來控制紅綠燈,以舒緩塞車情況。NVIDIA 使用 NVIDIA DGX SuperPOD,在破紀錄的 13.57 分鐘內便完成對 MiniGo AI 強化訓練模型的訓練。
咖啡還沒好,任務便完成:即時人工智慧基礎設施提供領先全球的效能表現
打破基準測試紀錄並非我們的目標,加速推動創新才是。這正是 NVIDIA 為什麼打造出功能強大且易於設定的DGX SuperPOD。使用者可以從 NGC 容器 registry 免費下載已完成優化的 CUDA-X AI 軟體,對 DGX SuperPOD 進行全面設定,便能立即享受到領先全球的人工智慧效能。
NVIDIA 與生態系中超過130萬名的 CUDA 開發者合作,致力於支援各種人工智慧框架及開發環境。
我們已經協助優化了數百萬行程式碼,無論是在雲端、資料中心或是網路邊緣,只要在能找到 NVIDIA GPU 的地方,我們的客戶便能夠部署其人工智慧專案。
人工智慧基礎設施現在已經夠快,未來還會更快
更棒的一點在於這個平台的速度還在不斷提升。NVIDIA 每個月都會發佈 CUDA-X AI 軟體最新的優化及效能增進內容,加上可以從 NGC 容器 registry 免費下載整合軟體堆疊,其中包括容器化的框架、預先訓練好的模型和腳本。拜 CUDA-X AI 軟體堆疊的創新內容所賜,NVIDIA DGX-2H 伺服器的 MLPerf 0.6 處理量較我們七個月前發佈的結果提升了 80%。
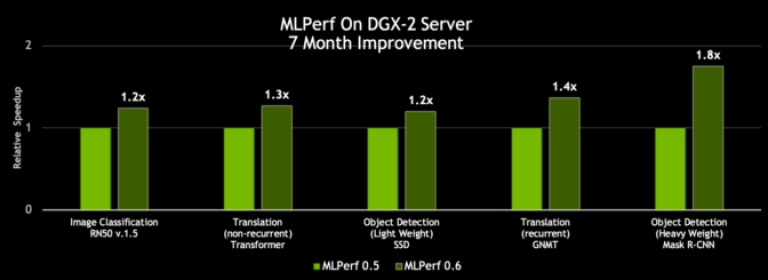 與同一時期單一 DGX-2H 伺服器的處理量相比,同一伺服器的效能提升達 80% (資料集單次通過神經網路) | MLPerf ID 0.5/0.6 比較:ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20
與同一時期單一 DGX-2H 伺服器的處理量相比,同一伺服器的效能提升達 80% (資料集單次通過神經網路) | MLPerf ID 0.5/0.6 比較:ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20這些成果加總起來,背後代表著數百億美元的投資和心力,這一切都是為了讓你能夠在今日快速完成工作,以及未來在更短的時間內完成工作。
- 發表您的看法
請勿張貼任何涉及冒名、人身攻擊、情緒謾罵、或內容涉及非法的言論。
請勿張貼任何帶有商業或宣傳、廣告用途的垃圾內容及連結。
請勿侵犯個人隱私權,將他人資料公開張貼在留言版內。
請勿重複留言(包括跨版重複留言)或發表與各文章主題無關的文章。
請勿張貼涉及未經證實或明顯傷害個人名譽或企業形象聲譽的文章。
您在留言版發表的內容需自負言論之法律責任,所有言論不代表PCDIY!雜誌立場,違反上述規定之留言,PCDIY!雜誌有權逕行刪除您的留言。
最近新增
- 《THE KING OF FIGHTERS AFK》最新更新 「洛克.霍華德」參戰!
- 《七騎士Re:BIRTH》最新更新 「戴倫斯」覺醒版本正式登場
- LG以ThinQ 擴展多元場域布局,打造智慧Villa生活體驗 「邦布BANGBU VILLA」正式開幕,演繹科技與自然共融的質感美學
- 威剛科技受邀參加CompuForum論壇 助力企業構築AI生態系
- 喝咖啡,也能像滑手機一樣簡單! 「飛利浦Baristina 一滑極萃義式咖啡機」全新上市 一按一滑一分鐘,極簡三步驟,讓新鮮義式咖啡優雅走進日常
- LG倡導「家電保養」新習慣!吸塵器保養需求大增286% 攜手全家推舊電池回收服務 從保養、節能到回收 打造家電生活循環
- NVIDIA下調Vera CPU搭載容量,凸顯LPDRAM供給缺口難弭平與中長期需求上揚趨勢
- 十銓科技強勢進軍 2026 歐洲國際防務展 Eurosatory 銓方位捍衛資安防線
- 搶攻618與暑假商機 「燦坤3C家電 x Lenovo五星級(有省錢)交心日」6/12重磅登場 AI PC需求升溫 帶動換機潮 燦坤買全球PC銷量第一Lenovo家用全品項獨家抽市值4.1萬AI筆電 指定機型送好禮 再享交心加購方案 指定筆電、平板登錄送意外損壞保固
- 演藝天后苗可麗成為「Ikarao 愛克拉」K 歌伴唱機台灣首位代言人 「愛克拉 就唱吧」鼓勵每個人隨時開唱 在台北捷運站尋找苗可麗身影 就有機會抽中價值破萬的 K 歌伴唱機!
- 友訊科技2026年第一季法人說明會 D-Link宣布跨足AI機器人市場 布局安全保護與智慧陪伴應用新藍海
- 三星揭曉2026 AI智慧顯示器全陣容 打造全方位AI日常
最多人點閱
- SP廣穎電通將於德國2015 Embedded World展示全方位工控系列產品
- InWin 805 NVIDIA EDITION機殼爆紅,迎廣GeForce GTX特仕版機箱正式開賣!
- 2024開學季筆電選購指南: 10大熱銷筆電推薦榜
- Windows 10 搭載 Office 版本聲明稿 Office Mobile 、 Office 2016 與 Office 365 版本差異說明
- 你的人生「升級」了沒?倒數十天!Windows 10開闊你的無限視野
- 全新Intel Core X系列處理器- Intel Core i9 極致版處理器 重裝上陣
- PLEXTOR展現軟實力,一舉推出三大獨家軟體
- JEDEC發布全新DDR5標準規範,從DDR5-4800起跳! 將加速導入下世代高效能電腦系統
- 不再是Toshiba品牌,全新Dynabook 2019 新品發布,透過運算與服務改變世界
- Mac 版 Office 2016 正式在台上市!
- microSD技術邁入第十年,SanDisk microSD記憶卡出貨量突破20億片
- 英特爾前進3D NAND,發表Intel SSD 600p、6000p、E 5420s、E 6000p、DC P3520、DC S3520固態硬碟!

