焦點
優化處理效率就是效能提升的秘密,Intel 解釋Alder Lake大、小核心的架構設計
文.圖/Lucky 2021-08-20 17:54:32
Intel在20號的清晨正式揭露了第12代處理器Alder Lake的技術細節,其中最大的改變就是製程從萬年14nm+++升級為Intel 7(原10nm+++),並且換上了大核心+小核心的全新架構設計,其中大核心Intel將其命名為「P-Core(效能核心)」、小核心則稱之為「E-Core(效率核心)」。

E-Core核心的分區規劃。
在設計上,利用更為精密的Intel 7製程,E-Core能夠容納更大的快取、更多的通道線路。首先在前端負責接收任務的指令快取(Instruction Cache)上,E-Core的容量擴增到了64KB,同時透過把目標快取分支的數量拉高到5,000條與縮短和指令快取的距離,讓指令的分析預測能有更高的效率和精準度,降低後期處理器做無用功的可能。
Intel把E-Core前端區域的指令快取加大到64KB,並讓目標快取的分支數量來到5,000個,配合指令預測功能,提高指令的準確度。
分析完指令後,接著就是將這些指令進行解碼,E-Core配置了2組3通道的Order Decode指令解碼區塊,能夠在單次週期處理6個指令。緊接著,在分派任務給處理單元的部分,Intel也把整個調配通道也加大,配置了5條分派通道(five-wide allocation)和8條引退通道(eight-wide retire)、256個條目亂序視窗(Entry Out Of Order Window)與8條執行埠(Execution Port)。
簡單來說,玩家可以想像一顆核心中有各式各樣的服務窗口,上述通道的功能則是各個窗口的指引和路線,而指令就要來辦理服務的民眾,透過增加更多的通道和指引就能讓指令可以更快更方便的找到對應的窗口,減少指令全部擠在單一通道,造成塞車、運算效率低落的問題。
Core-E擁有2組3通道指令解碼區塊,讓核心可以一次處理6道指令。
E-Core有5條分派通道、8條引退通道、256個條目亂序視窗、8條執行埠。
最後指令來到了處理核心的部分,Intel為E-Core規劃了4組ALU、2個Load AGU、2個Stored AGU、2個Jump Port、2個Integer Store Data、2個FP/Vec Store Data 、2個FP/Vec stacks、3rd Vec ALU,總計17個執行埠(玩家可以想像成不同服務項目的櫃檯數量)。
E-Core各項處理單元的配置。
比較特別的是,Inte配置了2組Load/Store AGU,還將L2快取容量加大為4MB,配合更深的緩衝、更先進的預先取用機制,以此來達到更好的處理效率,另外搭配Intel Resource Director技術,讓軟體可以直接管控這些核心的執行緒,達到公平分配工作量的效果,防止傳說中「一核有難,全核圍觀」的問題。
E-Core個別配置了2組Load AGU和Store AGU,搭配大容量的4MB L2快取,提供更好的處理效率,還可以利用Intel Resource Director技術讓軟體直接管理執行緒,達到更公平的資源分配。
而在安全防護性上,Intel為E-Core加入多種安全功能的支援,包含Intel Control-Flow Enforcement Technology 以及 Intel Virtualization Technology Redirection Protection、FMA、VNNI。
核心也有多樣化的硬體安全防護功能。
E-Core各區單元一覽。
以效能來說,E-Core對比2015年的Skylake架構處理器在1C/1T的模式下,在同功耗下有著40%的效能提升,反之在相同效能的前提下則能省電40%。而在相同執行續數量的比較模式下,4C4T的E-Core則不論是效能還是省電上都比2C/4T的Skylake好上80%,也就是4顆E-Core加起來不僅比兩顆Skylake省電,效能還更強。
在都是1C/1T的情況下,E-Core比Skylake要有40%的效能/省電的效率。
若是將標準改為都是4執行緒的情況下,E-Core即使是4C/4T,在省電和效能更是大勝2C/4T的Skylake處理器80%之多。
P-Core各區的功能一覽。
在內部設計上,負責接收指令的核心前端被大幅度加大、加深,以此來容納更多處理單位,像是4K指令緩衝區(4K iTLB)從128提升為256、目標快取的分支從5,000個暴增到12,000個,並透過更智慧的分支預測、降低L1快取延遲、L2 全快取寫入預測及頻寬最佳化等方式,創造更快更有效率的指令處理效率。
利用Intel 7製程更精密的優勢,前端能夠容納更多處理單位,像是4K iLTB緩衝快取從128提升為256、解碼單元從16組提升到了32組等。
當然,尺寸加大的不只是前端的區塊,其他諸如負責指令解碼的Decode核心從4個增加到6個,負責任務分配的Out Of Order Engine也加寬到6組分派通道(six-wide allocation)、12組執行埠(Execution Port),同時更深的512-entry Reorder-Buffer緩衝換來更大的Scheduler調度緩衝空間,讓更多的指令可以處在rename / allocation階段。
指令分派的Out Of Order Engine加寬到6組分派通道、12組執行埠,容量更大的512-entry Reorder-Buffer和Scheduler調度緩衝空間能夠容許更多指令處在rename / allocation階段。
最後來到負責執行的處理單元,P-Core擁有5組ALU整數邏輯單元、Vector 運算則有了效率更快、延遲更低的FADD單元輔助,FMA指令集單元則是能夠支援FP16資料格式和Intel近來喜愛主打的AVX-512指令集,同時隨著處理單元的變多,L1和L2快取在尺寸和容量上也相應的增大。
P-Core擁有5組ALU整數邏輯單元。
核心加入了FADD單元提供有效率、延遲更低的運算;FMA單元能夠支援FP16資料格式和AVX-512指令集。
L1快取通道從2組變為3組,容量也有所增加。
L2快去的尺寸大幅加大,容量也來到2MB。
P-Core各個單元一覽。
除此之外,P-Core還加入全新的Advanced Matrix Extensions(AMX)技術,這是針對下一代深度學習所打造,就由內建AI加速器的形式,能夠大幅度的提升矩陣乘法運算速度。
AMX技術能夠加速深度運算學習,強法矩陣乘法運算速度。
P-Core在新製程、新架構的加持下,對比11代的Rocket Lake能夠有著19%的IPC指令週期的提升。若再加上針對Windows 11系統所特別設計的Intel Thread Director功能,讓每顆核心的資源可以隨心所欲的調動,由低延遲與彈性調動的方式,讓Alder Lake能夠徹底發揮大核+小核配置效能優勢。
P-Core的整體IPC效能將比上一代Rocket Lake高出19%。
★快來追蹤/加入我們!!!
FB玩家社團:PCDIY!玩家FB社團
Instagram頻道:pcdiytw

效率核心,E-Core
Alder Lake的E-Core使用了代號為「Gracemont」的架構,追求以最少的功耗達到更高的指令吞吐效率,全系列的Alder Lake處理器不論是桌機還是行動裝置都擁有相同的8核心E-Core配置,但由於此架構本身是為輕度工作需求,所以將不具備多執行緒(Thread)功能。 E-Core核心的分區規劃。
E-Core核心的分區規劃。在設計上,利用更為精密的Intel 7製程,E-Core能夠容納更大的快取、更多的通道線路。首先在前端負責接收任務的指令快取(Instruction Cache)上,E-Core的容量擴增到了64KB,同時透過把目標快取分支的數量拉高到5,000條與縮短和指令快取的距離,讓指令的分析預測能有更高的效率和精準度,降低後期處理器做無用功的可能。
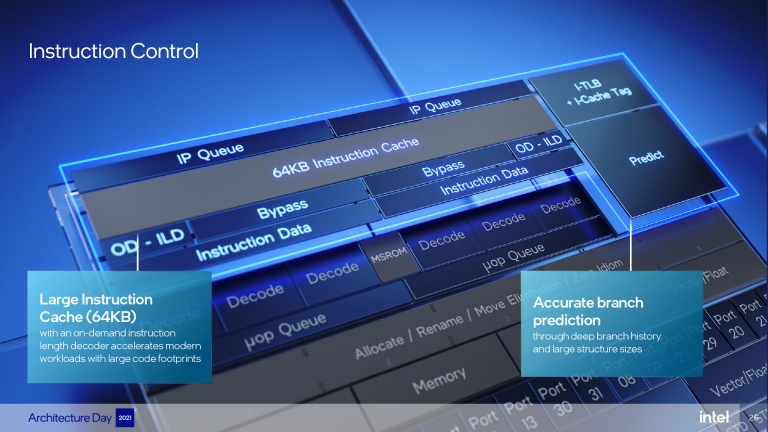 Intel把E-Core前端區域的指令快取加大到64KB,並讓目標快取的分支數量來到5,000個,配合指令預測功能,提高指令的準確度。
Intel把E-Core前端區域的指令快取加大到64KB,並讓目標快取的分支數量來到5,000個,配合指令預測功能,提高指令的準確度。分析完指令後,接著就是將這些指令進行解碼,E-Core配置了2組3通道的Order Decode指令解碼區塊,能夠在單次週期處理6個指令。緊接著,在分派任務給處理單元的部分,Intel也把整個調配通道也加大,配置了5條分派通道(five-wide allocation)和8條引退通道(eight-wide retire)、256個條目亂序視窗(Entry Out Of Order Window)與8條執行埠(Execution Port)。
簡單來說,玩家可以想像一顆核心中有各式各樣的服務窗口,上述通道的功能則是各個窗口的指引和路線,而指令就要來辦理服務的民眾,透過增加更多的通道和指引就能讓指令可以更快更方便的找到對應的窗口,減少指令全部擠在單一通道,造成塞車、運算效率低落的問題。
 Core-E擁有2組3通道指令解碼區塊,讓核心可以一次處理6道指令。
Core-E擁有2組3通道指令解碼區塊,讓核心可以一次處理6道指令。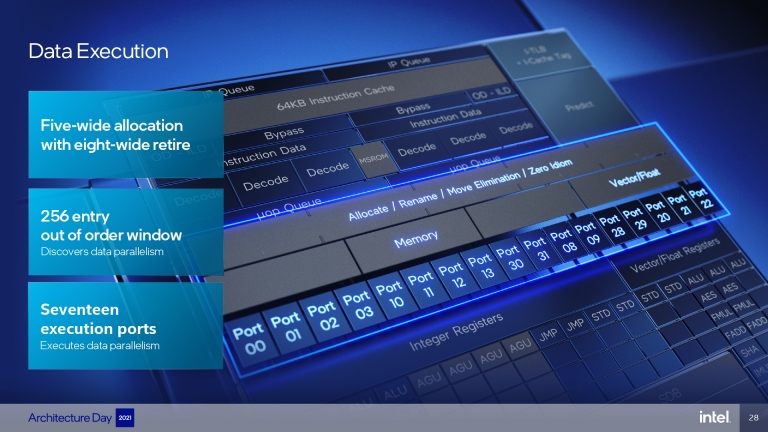 E-Core有5條分派通道、8條引退通道、256個條目亂序視窗、8條執行埠。
E-Core有5條分派通道、8條引退通道、256個條目亂序視窗、8條執行埠。最後指令來到了處理核心的部分,Intel為E-Core規劃了4組ALU、2個Load AGU、2個Stored AGU、2個Jump Port、2個Integer Store Data、2個FP/Vec Store Data 、2個FP/Vec stacks、3rd Vec ALU,總計17個執行埠(玩家可以想像成不同服務項目的櫃檯數量)。
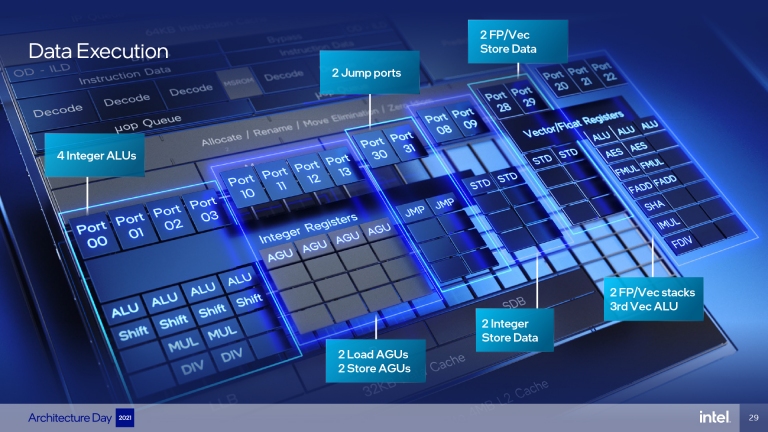 E-Core各項處理單元的配置。
E-Core各項處理單元的配置。比較特別的是,Inte配置了2組Load/Store AGU,還將L2快取容量加大為4MB,配合更深的緩衝、更先進的預先取用機制,以此來達到更好的處理效率,另外搭配Intel Resource Director技術,讓軟體可以直接管控這些核心的執行緒,達到公平分配工作量的效果,防止傳說中「一核有難,全核圍觀」的問題。
 E-Core個別配置了2組Load AGU和Store AGU,搭配大容量的4MB L2快取,提供更好的處理效率,還可以利用Intel Resource Director技術讓軟體直接管理執行緒,達到更公平的資源分配。
E-Core個別配置了2組Load AGU和Store AGU,搭配大容量的4MB L2快取,提供更好的處理效率,還可以利用Intel Resource Director技術讓軟體直接管理執行緒,達到更公平的資源分配。而在安全防護性上,Intel為E-Core加入多種安全功能的支援,包含Intel Control-Flow Enforcement Technology 以及 Intel Virtualization Technology Redirection Protection、FMA、VNNI。
 核心也有多樣化的硬體安全防護功能。
核心也有多樣化的硬體安全防護功能。 E-Core各區單元一覽。
E-Core各區單元一覽。以效能來說,E-Core對比2015年的Skylake架構處理器在1C/1T的模式下,在同功耗下有著40%的效能提升,反之在相同效能的前提下則能省電40%。而在相同執行續數量的比較模式下,4C4T的E-Core則不論是效能還是省電上都比2C/4T的Skylake好上80%,也就是4顆E-Core加起來不僅比兩顆Skylake省電,效能還更強。
 在都是1C/1T的情況下,E-Core比Skylake要有40%的效能/省電的效率。
在都是1C/1T的情況下,E-Core比Skylake要有40%的效能/省電的效率。 若是將標準改為都是4執行緒的情況下,E-Core即使是4C/4T,在省電和效能更是大勝2C/4T的Skylake處理器80%之多。
若是將標準改為都是4執行緒的情況下,E-Core即使是4C/4T,在省電和效能更是大勝2C/4T的Skylake處理器80%之多。效能核心,P-Core
看完了E-Core小核心,來看看代號為「Golden Cove」的P-Core大核心這邊,其目的專注於更低的延遲、更高的時脈,為極限的效能而生,也因此P-Core的面積要比E-Core大上不少,並支援多執行緒功能,但相對的所需功耗和帶來的發熱也就跟著大幅提高,這也是為何不同等級的處理器產品所配置的P-Core數量會有所不同,其中主機平台的P-Core數量達到8C/16T、筆電為6C/12T、行動裝置則只剩下2C/4T。 P-Core各區的功能一覽。
P-Core各區的功能一覽。在內部設計上,負責接收指令的核心前端被大幅度加大、加深,以此來容納更多處理單位,像是4K指令緩衝區(4K iTLB)從128提升為256、目標快取的分支從5,000個暴增到12,000個,並透過更智慧的分支預測、降低L1快取延遲、L2 全快取寫入預測及頻寬最佳化等方式,創造更快更有效率的指令處理效率。
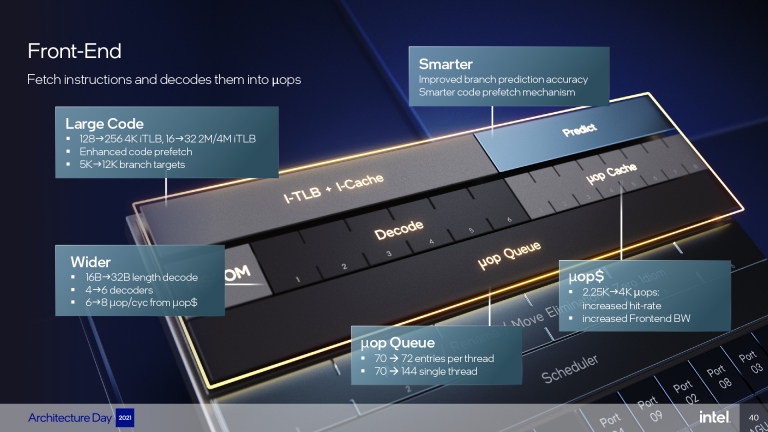 利用Intel 7製程更精密的優勢,前端能夠容納更多處理單位,像是4K iLTB緩衝快取從128提升為256、解碼單元從16組提升到了32組等。
利用Intel 7製程更精密的優勢,前端能夠容納更多處理單位,像是4K iLTB緩衝快取從128提升為256、解碼單元從16組提升到了32組等。當然,尺寸加大的不只是前端的區塊,其他諸如負責指令解碼的Decode核心從4個增加到6個,負責任務分配的Out Of Order Engine也加寬到6組分派通道(six-wide allocation)、12組執行埠(Execution Port),同時更深的512-entry Reorder-Buffer緩衝換來更大的Scheduler調度緩衝空間,讓更多的指令可以處在rename / allocation階段。
 指令分派的Out Of Order Engine加寬到6組分派通道、12組執行埠,容量更大的512-entry Reorder-Buffer和Scheduler調度緩衝空間能夠容許更多指令處在rename / allocation階段。
指令分派的Out Of Order Engine加寬到6組分派通道、12組執行埠,容量更大的512-entry Reorder-Buffer和Scheduler調度緩衝空間能夠容許更多指令處在rename / allocation階段。最後來到負責執行的處理單元,P-Core擁有5組ALU整數邏輯單元、Vector 運算則有了效率更快、延遲更低的FADD單元輔助,FMA指令集單元則是能夠支援FP16資料格式和Intel近來喜愛主打的AVX-512指令集,同時隨著處理單元的變多,L1和L2快取在尺寸和容量上也相應的增大。
 P-Core擁有5組ALU整數邏輯單元。
P-Core擁有5組ALU整數邏輯單元。 核心加入了FADD單元提供有效率、延遲更低的運算;FMA單元能夠支援FP16資料格式和AVX-512指令集。
核心加入了FADD單元提供有效率、延遲更低的運算;FMA單元能夠支援FP16資料格式和AVX-512指令集。 L1快取通道從2組變為3組,容量也有所增加。
L1快取通道從2組變為3組,容量也有所增加。 L2快去的尺寸大幅加大,容量也來到2MB。
L2快去的尺寸大幅加大,容量也來到2MB。 P-Core各個單元一覽。
P-Core各個單元一覽。除此之外,P-Core還加入全新的Advanced Matrix Extensions(AMX)技術,這是針對下一代深度學習所打造,就由內建AI加速器的形式,能夠大幅度的提升矩陣乘法運算速度。
 AMX技術能夠加速深度運算學習,強法矩陣乘法運算速度。
AMX技術能夠加速深度運算學習,強法矩陣乘法運算速度。P-Core在新製程、新架構的加持下,對比11代的Rocket Lake能夠有著19%的IPC指令週期的提升。若再加上針對Windows 11系統所特別設計的Intel Thread Director功能,讓每顆核心的資源可以隨心所欲的調動,由低延遲與彈性調動的方式,讓Alder Lake能夠徹底發揮大核+小核配置效能優勢。
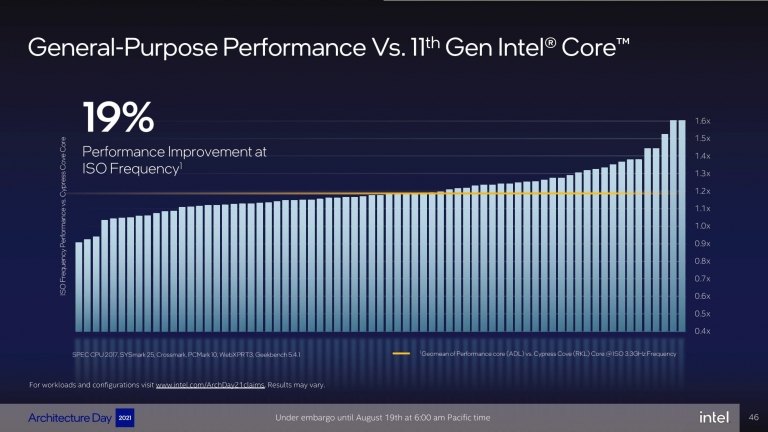 P-Core的整體IPC效能將比上一代Rocket Lake高出19%。
P-Core的整體IPC效能將比上一代Rocket Lake高出19%。★快來追蹤/加入我們!!!
FB玩家社團:PCDIY!玩家FB社團
Instagram頻道:pcdiytw
- 發表您的看法
請勿張貼任何涉及冒名、人身攻擊、情緒謾罵、或內容涉及非法的言論。
請勿張貼任何帶有商業或宣傳、廣告用途的垃圾內容及連結。
請勿侵犯個人隱私權,將他人資料公開張貼在留言版內。
請勿重複留言(包括跨版重複留言)或發表與各文章主題無關的文章。
請勿張貼涉及未經證實或明顯傷害個人名譽或企業形象聲譽的文章。
您在留言版發表的內容需自負言論之法律責任,所有言論不代表PCDIY!雜誌立場,違反上述規定之留言,PCDIY!雜誌有權逕行刪除您的留言。
最近新增
- 「QNAP 威聯通」COMPUTEX 2026 大放異彩,以「READY 高可用性,全面就緒 RECOVERY 即刻救援,絕不妥協 專為 AI 時代而生」為主題,宣示「賦能 AI 新時代」!
- 華星光電IJP OLED將於2026下半年導入品牌監視器及筆電產品,韓系主導格局迎來挑戰
- 微軟推出專為效能與靈活性設計的全新 Surface Pro 與 Surface Laptop
- XPG 擴大散熱產品佈局!MAESTRO 風冷與 INFINITY 風扇系列全新上市 賦予玩家無限改裝創意 輕鬆升級極致效能與美學
- 台灣微軟新聞稿 微軟宣布正式推出 Copilot Cowork
- 效能、潮流輾壓式升級 ROG STRIX SCAR 18電競神裝覺醒
- AI時代帶動家庭網路升級潮 凱擘大寬頻搶攻618商機 推雙向1G對稱頻寬月付$999
- 【挑戰 1000 萬張-顯示卡-拆解記錄:000-000-018】微星 MSI GeForce RTX 5090 32G LIGHTNING Z 閃電卡皇:台灣代理商建達公司貨:台灣製造 Made In Taiwan(限定版→僅開箱)
- D-Link 友訊科技 2026年第一季法人說明會 Q1營運穩健成長 AI智慧聯網與AI機器人雙軌布局
- 家電難免有突發時刻!LG Care寄存+跨界攜手「全家」神救援 全台超過4,400間店舖化身「臨時冰箱」 維修期食材保鮮不求人
- 村田製作所攜手新思科技,透過電磁與熱解析工具提供模擬模型
- 年中回饋最大檔!MSI 618 購物戰開跑 熱銷明星效能筆電、AI電競掌機限時優惠,升級配備正是時候
最多人點閱
- GIGABYTE GeForce GTX 1070 Xtreme Gaming實測開箱,電競級顯示卡中的頂尖之作!
- Seagate IRONWOLF 10TB機械硬碟實測開箱,氦氣填充那嘶狼守護者NAS HDD
- AMD Radeon RX 480實測開箱,玩家級顯示卡重返榮耀!
- 「浦科特 PLEXTOR S2C 512GB SSD」實測開箱,超值型固態硬碟中的優質好貨!
- 洋垃圾神器,Xeon E5-2670實測開箱大作戰!
- MSI CORE FROZR L CPU散熱器實測開箱,微星電競產品再添新兵
- MSI GeForce GTX 1060 GAMING X 6G實測開箱,玩家級電競顯示卡中的神兵利器!
- ASUS ROG STRIX-GTX1080-O8G-GAMING開箱實測,旗艦三風扇電競顯示卡中的頂尖之作!
- MSI GeForce GTX 1080 GAMING X 8G實測開箱,史上最強大Pascal自製顯示卡全面來襲!
- 淘寶網洋垃圾再顯神威,1999元買到8核心16執行緒Xeon E5-2670神器級處理器!
- MSI GeForce GTX 1050 Ti GAMING X 4G實測開箱,中階電競顯示卡中的玩家精品!
- 微星MSI Aegis X-026TW快打旋風V同梱版實測開箱,VR電競桌機的頂尖之作!

