焦點
素描秒變照片,NVIDIA GauGAN帶領AI應用邁向可視創作應用,首席研究員現身說法
文.圖/Johan 2019-10-07 18:00:00
這幾年吵了很久的AI (Artificial Intelligence,人工智慧),到底真正能幫助到人們什麼呢?除了手機喊AI、3C喊AI、汽車也要AI,就連IoT (物聯網)也要搭AI熱潮而創造出一個全新的AIoT (即AI + IoT,人工智能物聯網)名詞,才好像不會跟這個強調AI的世界脫勾一樣。
但是仔細看看,AI到底能做些什麼?除了像是手機的自動場景判別、自動分類、甚至Google Pixel手機也導入AI軟體應用,能讓一般鏡頭拍攝並經由計算後產生有淺景深效果的照片,讓人覺得AI似乎可以在攝影上面幫上許多忙。然而AI的應用其實不只這些,雖說很多更深入的AI研究計畫與應用幾乎在實驗室內進行,透過超昂貴的AI級伺服器來進行計算與訓練,這些研究成果也不一定是普羅大眾會注意到的部份,而為讓AI的應用更多元、有趣,且實用化,NVIDIA推出了GauGAN技術,讓大家也能輕鬆運用AI所帶來的優勢,來做更有趣的事情!
 NVIDIA推出GauGAN應用軟體,該示範軟體如同微軟小畫家(MS Paint)再加入AI基因,讓使用者只要簡單構圖,就能在幾秒內產生出栩栩如生的照片級圖畫
NVIDIA推出GauGAN應用軟體,該示範軟體如同微軟小畫家(MS Paint)再加入AI基因,讓使用者只要簡單構圖,就能在幾秒內產生出栩栩如生的照片級圖畫
這次要介紹的就是NVIDIA Research於GTC 2019正式公佈的GauGAN,也就是一種只要用戶提供簡單的素描,即可產生出如照片般栩栩如生的圖畫,可以幫助創作者激發出更多的創意,亦可發揮初一般用戶有趣的構圖應用,成為可視化AI應用中,最能與生活創意結合的絕佳應用案例。
▼ GauGAN的使用示範影片
這個GanGAN計畫,是來自NVIDIA和MIT的研究團隊所共同執行的成果,組成的團員皆是華人/韓國人,包含NVIDIA的劉洺堉(Ming-Yu Liu)、王鼎鈞(Ting-Chun Wang),以及來自 MIT 的朱俊彥(Jun-Yan Zhu)和UC Berkeley的Taesung Park等。可以參考他們的GitHub網頁:
劉洺堉 (Ming-Yu Liu)的GitHub頁面: 這裡
王鼎鈞 (Ting-Chun Wang) 的GitHub頁面: 這裡
朱俊彥 (Jun-Yan Zhu)的GitHub頁面: 這裡
박태성 (Taesung Park)的GitHub頁面: 這裡
取名為GauGAN (高竿),主要是紀念法國印象派畫家高更(Gauguin),並加上GAN (Generative Adversarial Networks,生成對抗網路) 的字首,所形成的全新字彙,也是該應用所使用到的主要技術。
有關於更多NVIDIA GauGAN相關報導,請參考下方文章:
● 為想像力增添色彩:GauGAN AI 藝術工具創造出超過五十萬個影像
● NVIDIA Research 在 SIGGRAPH 展出令人驚豔的開創性研究成果
當然不只自然圖片,包括人臉也能隨機產生,此外該團隊還有另一項研究計畫,叫做PetSwap,可以只要輸入一個原始動物照片,就能產生出其他不同動物,但表情類似的照片,甚至可以產生動畫,讓AI應用更加有趣!
由NVIDIA Research首席研究員劉洺堉先生,來親自講解並示範GauGAN的功能
那麼GauGAN技術是如何幫助用戶產生這樣的照片(或動畫)呢?當然得先從其技術來研究,這次由NVIDIA Research首席研究員劉洺堉先生,來親自講解並示範GauGAN的功能,其中也包括了主要應用原理的簡述 (這裡僅簡單做簡述而已,因為光是簡述與原理就很複雜了,有興趣深度研究者,可參考其相關Paper文件),讓讀者能大致了解該技術運用到的原理與解決方式,以讓開啟大家對於這項技術的認知與應用。
這裡講述的是GanGAN與其運用到的主要技術:SPADE (SPatially Adaptive DEnormalization,空間適應去正規化),搭配BN (Batch Normalization,批次正規化)技術的優點,讓產生出來的結果是在能夠控制的範圍,以產生出使用者所要表達的目標圖片。
以下就透過劉先生的簡報,來了解GauGAN的運作原理吧 (註:很燒腦,請斟酌服用):
這次講解的主題,就是GanGAN/SPADE所使用到的「空間適應正規化之語意影像合成」技術
人類的作畫演進史:從最早的洞穴石畫開始,到近世紀使用畫筆來作畫,直到近30年來數位革命後,可透過電腦來作畫。近期則是因應AI革命,以後作畫只要搭配NVIDIA GauGAN技術來簡單素描,就可以輕鬆產生出如照片等級的圖畫
GauGAN既然能自行合成出如真實照片一般的圖畫,那麼其運用到的技術,就有包含有監控和未受監控的技術,左側是配對好、有監控下,指示GauGAN依照我們需求來繪製出想要的圖形場景,而右側是未配對與未規範下,繪製出來的結果就會有各種結果
這是NVIDIA GauGAN的軟體使用畫面,左側可以當作規範用的原始圖像語意,搭配所需要的素材(例如圖中灰色的石頭),來產生出右側在規範下的合成圖片
這些是各網友透過GauGAN所產生的各種合成圖片範例
透過GauGAN的幫助,讓一些Concept Arts (概念畫作)作者能夠專注在本體(如左圖的飛船和右邊的城堡)的繪製,背景合成就交給GauGAN去負責即可,以加速作品的完成
當然一些海報,尤其是科幻類的,只要提供好的素材,透過GauGAN也能輕鬆產生如真實般的圖片
這兩張圖原本是一連串動畫,透過左邊的不同素描,即可產生出如電影般的場景。不過劉洺堉表示目前的模型下,由於圖是個別依照原素材產生的,因此像是左圖的光澤與波浪是沒有連續性的,但可以先給導演或是製片一個方向,而這部份未來也是有機會克服的
深度生成模型。上述是一般的原始圖像搭配亂數點,套用在三維圖像模型,可生成新的2D高斯模型。同理,下方的原始照片,透過AI運算,即可產生新的影像
GAN (生成對抗網路)的模型就是,上述的圖片表示在沒有原始圖像時,產生器(Generator)只能產出無意義的亂碼圖,此時經過判別器(Discriminator)判定因為沒有人頭像,所以失敗!這樣就必須重新生成。而下方是提供各種原始頭像圖,經過產生器產生出我們規定想要的圖片後,經由判別器判定為「真」,代表成功生成。
當原始人像取樣圖越多的時候,透過產生器的取樣,即可生成出各式各樣的臉譜與表情(右邊的照片都是電腦生成的,不是真實世界拍攝的人臉哦!)
條件式GAN的模型,就是如上述的模型,而取樣則是依照不同設定條件來取樣
而NVIDIA條件式GAN的模型,就是以分割圖遮罩(Segmentation Mask)作法,z為原始圖庫,y為設定條件。例如上圖的綠色區設定成樹木、淺綠區設定成草地、灰色區為天空,透過產生器之後,即可生成如右上圖那樣的場景。以下類推!
這是pix2pixHD (圖素點轉成高清圖素)的產生器設計模型,更多細節可參考這裡的白皮書
左邊是給予一些標記,右邊則是合成出來的圖片
這些也都是條件式GAN的模型與生成圖片範例
說到這裡,就不得不先提到BN (批次正規化),這原先是由Google在2015年提出,是一種深度學習網路的訓練技巧之一,可以加快模型的收斂速度,提升效能。這裡是BN的模型簡介
為什麼GauGAN要使用到BN模型,因為一開始的假設,是要減少協方差內部活動的轉變,如右上沒使用BN時,生成的圖片會變得很奇怪,採用BN後,表面變得比較單一光滑且單純。因此新的假設就是:讓風景照潤飾得更平滑,並促使權重空間往長度方向做去耦合,讓收斂速度更快
不過使用BN模型也有些小問題,就是往往會洗掉一些語意輸入訊息,導致生產圖片的畫質下降(參考上述的圖)
因此必須搭配SPADE技術,來讓生成畫面更接近原始語意所要表達的重點。例如這裡的說明,若單獨透過pix2pixHD之下,生成的圖就可能出現灰色的狀況(語意被洗掉了),而搭配SPADE之後,就能清楚告訴產生器要生成的正確圖像
再搭配「分割圖遮罩」技術,通常包含了超大單一區域的範圍與語意描述,即可生成更精準的目標圖像
這是BN和SPADE的公式模型比較。且空間變化量,取決於輸入的分割圖遮罩,而正規化所洗掉的資訊還可透過Gamma值和Beta值補貼回來
這就是SPADE的模組簡述
透過上述的模型,發展出以SPADE為主的圖像產生器
而NVIDIA的GauGAN,便是基於SPADE為基礎的框架
如此一來,只要設定好分割圖遮罩,即可生成出用戶想要的目標照片。並不限定風景照,就算是室內照片,也都能輕鬆繪製
室外風景,也都能如所需要來生成
當然動物也能完美生成
透過可變式學習框架,來進行樣式控制學習
因此只要有標記和地面真實性,就能生成出不同的目標圖片 (有暗有明)
此外在測試過程中,我們可以使用不同樣式影像來控制輸出圖的全域色調
這裡就是引用原始圖片的色調,來為輸出圖形的色調進行調整,成為GauGAN最終的輸出圖片
以上,就是GauGAN所使用到的各種模型與深度學習網路。在圖片的大數據中,劉洺堉表示,目前NVIDIA GanGAN的雲端資料庫照片共有超過500萬張,這些皆是來自flickr或是其他有授權的圖片。而每當使用者將素描語意檔上傳並送至NVIDIA的GauGAN伺服器進行分析之後,GauGAN會從已經透過過深度學習訓練後的100萬張圖當中,挑出最符合語意的照片素材,以合成出最適合的照片組成,最後再調整色調,讓整張照片看起來沒問題之後,再回傳給使用者。
最後,提供與GauGAN與PetSwap的相關網站,讓使用者親自去體驗看看吧!
● GauGAN遊樂場: http://nvidia-research-mingyuliu.com/gaugan/
另外的PetSwap,可以輸入一個原始動物照片,然後圈選頭部範圍,就能產生出其他不同動物,但表情類似的照片,讓AI應用更加有趣!
● PetSwap遊樂場: http://nvidia-research-mingyuliu.com/petswap
但是仔細看看,AI到底能做些什麼?除了像是手機的自動場景判別、自動分類、甚至Google Pixel手機也導入AI軟體應用,能讓一般鏡頭拍攝並經由計算後產生有淺景深效果的照片,讓人覺得AI似乎可以在攝影上面幫上許多忙。然而AI的應用其實不只這些,雖說很多更深入的AI研究計畫與應用幾乎在實驗室內進行,透過超昂貴的AI級伺服器來進行計算與訓練,這些研究成果也不一定是普羅大眾會注意到的部份,而為讓AI的應用更多元、有趣,且實用化,NVIDIA推出了GauGAN技術,讓大家也能輕鬆運用AI所帶來的優勢,來做更有趣的事情!
 NVIDIA推出GauGAN應用軟體,該示範軟體如同微軟小畫家(MS Paint)再加入AI基因,讓使用者只要簡單構圖,就能在幾秒內產生出栩栩如生的照片級圖畫
NVIDIA推出GauGAN應用軟體,該示範軟體如同微軟小畫家(MS Paint)再加入AI基因,讓使用者只要簡單構圖,就能在幾秒內產生出栩栩如生的照片級圖畫GauGAN技術說明會,講述其功能與部份原理
NVIDIA一直以來總是在消費性GPU上取得了領先的市場地位,賦予玩家們最快最棒的遊戲玩樂體驗,近年來透過GPGPU的應用以及其CUDA架構,更是在AI領域取得市場先機,獲得全世界不少研究機構與企業的青睞,成為當今AI領域的霸主之一。為讓其GPGPU產品發揮強大的運算效能,NVIDIA內部也有不少與AI領域相關的研究計畫與應用。這次要介紹的就是NVIDIA Research於GTC 2019正式公佈的GauGAN,也就是一種只要用戶提供簡單的素描,即可產生出如照片般栩栩如生的圖畫,可以幫助創作者激發出更多的創意,亦可發揮初一般用戶有趣的構圖應用,成為可視化AI應用中,最能與生活創意結合的絕佳應用案例。
▼ GauGAN的使用示範影片
這個GanGAN計畫,是來自NVIDIA和MIT的研究團隊所共同執行的成果,組成的團員皆是華人/韓國人,包含NVIDIA的劉洺堉(Ming-Yu Liu)、王鼎鈞(Ting-Chun Wang),以及來自 MIT 的朱俊彥(Jun-Yan Zhu)和UC Berkeley的Taesung Park等。可以參考他們的GitHub網頁:
劉洺堉 (Ming-Yu Liu)的GitHub頁面: 這裡
王鼎鈞 (Ting-Chun Wang) 的GitHub頁面: 這裡
朱俊彥 (Jun-Yan Zhu)的GitHub頁面: 這裡
박태성 (Taesung Park)的GitHub頁面: 這裡
取名為GauGAN (高竿),主要是紀念法國印象派畫家高更(Gauguin),並加上GAN (Generative Adversarial Networks,生成對抗網路) 的字首,所形成的全新字彙,也是該應用所使用到的主要技術。
有關於更多NVIDIA GauGAN相關報導,請參考下方文章:
● 為想像力增添色彩:GauGAN AI 藝術工具創造出超過五十萬個影像
● NVIDIA Research 在 SIGGRAPH 展出令人驚豔的開創性研究成果
GauGAN技術說明會,NVIDIA首席研究員技術開講
GauGAN就如同一枝「智能畫筆」(Smart Paintbrush),透過NVIDIA在雲端資料圖所提供的GAN(生成對抗網路)的訓練結果,讓使用者只要簡單繪製幾個分割圖(Segmentation Map)並填入不同的顏色細節以顯示出該場景中各圖素的對應位置,搭配選擇不同效果濾鏡,即可自動產生出目標的專業照片級的圖片。當然不只自然圖片,包括人臉也能隨機產生,此外該團隊還有另一項研究計畫,叫做PetSwap,可以只要輸入一個原始動物照片,就能產生出其他不同動物,但表情類似的照片,甚至可以產生動畫,讓AI應用更加有趣!
 由NVIDIA Research首席研究員劉洺堉先生,來親自講解並示範GauGAN的功能
由NVIDIA Research首席研究員劉洺堉先生,來親自講解並示範GauGAN的功能那麼GauGAN技術是如何幫助用戶產生這樣的照片(或動畫)呢?當然得先從其技術來研究,這次由NVIDIA Research首席研究員劉洺堉先生,來親自講解並示範GauGAN的功能,其中也包括了主要應用原理的簡述 (這裡僅簡單做簡述而已,因為光是簡述與原理就很複雜了,有興趣深度研究者,可參考其相關Paper文件),讓讀者能大致了解該技術運用到的原理與解決方式,以讓開啟大家對於這項技術的認知與應用。
這裡講述的是GanGAN與其運用到的主要技術:SPADE (SPatially Adaptive DEnormalization,空間適應去正規化),搭配BN (Batch Normalization,批次正規化)技術的優點,讓產生出來的結果是在能夠控制的範圍,以產生出使用者所要表達的目標圖片。
以下就透過劉先生的簡報,來了解GauGAN的運作原理吧 (註:很燒腦,請斟酌服用):
 這次講解的主題,就是GanGAN/SPADE所使用到的「空間適應正規化之語意影像合成」技術
這次講解的主題,就是GanGAN/SPADE所使用到的「空間適應正規化之語意影像合成」技術 人類的作畫演進史:從最早的洞穴石畫開始,到近世紀使用畫筆來作畫,直到近30年來數位革命後,可透過電腦來作畫。近期則是因應AI革命,以後作畫只要搭配NVIDIA GauGAN技術來簡單素描,就可以輕鬆產生出如照片等級的圖畫
人類的作畫演進史:從最早的洞穴石畫開始,到近世紀使用畫筆來作畫,直到近30年來數位革命後,可透過電腦來作畫。近期則是因應AI革命,以後作畫只要搭配NVIDIA GauGAN技術來簡單素描,就可以輕鬆產生出如照片等級的圖畫 GauGAN既然能自行合成出如真實照片一般的圖畫,那麼其運用到的技術,就有包含有監控和未受監控的技術,左側是配對好、有監控下,指示GauGAN依照我們需求來繪製出想要的圖形場景,而右側是未配對與未規範下,繪製出來的結果就會有各種結果
GauGAN既然能自行合成出如真實照片一般的圖畫,那麼其運用到的技術,就有包含有監控和未受監控的技術,左側是配對好、有監控下,指示GauGAN依照我們需求來繪製出想要的圖形場景,而右側是未配對與未規範下,繪製出來的結果就會有各種結果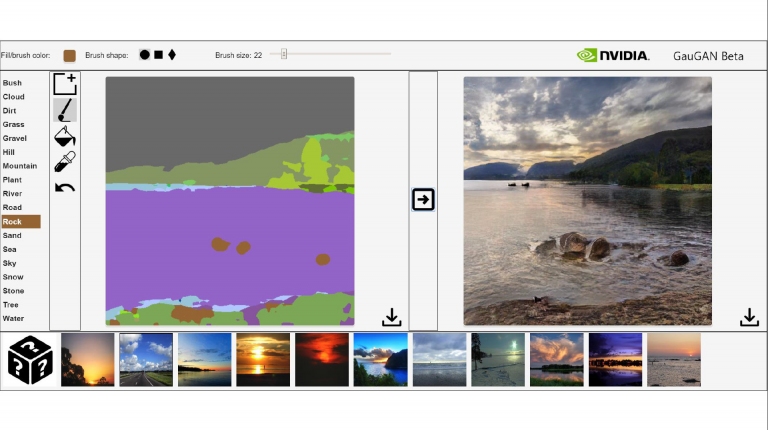 這是NVIDIA GauGAN的軟體使用畫面,左側可以當作規範用的原始圖像語意,搭配所需要的素材(例如圖中灰色的石頭),來產生出右側在規範下的合成圖片
這是NVIDIA GauGAN的軟體使用畫面,左側可以當作規範用的原始圖像語意,搭配所需要的素材(例如圖中灰色的石頭),來產生出右側在規範下的合成圖片 這些是各網友透過GauGAN所產生的各種合成圖片範例
這些是各網友透過GauGAN所產生的各種合成圖片範例 透過GauGAN的幫助,讓一些Concept Arts (概念畫作)作者能夠專注在本體(如左圖的飛船和右邊的城堡)的繪製,背景合成就交給GauGAN去負責即可,以加速作品的完成
透過GauGAN的幫助,讓一些Concept Arts (概念畫作)作者能夠專注在本體(如左圖的飛船和右邊的城堡)的繪製,背景合成就交給GauGAN去負責即可,以加速作品的完成 當然一些海報,尤其是科幻類的,只要提供好的素材,透過GauGAN也能輕鬆產生如真實般的圖片
當然一些海報,尤其是科幻類的,只要提供好的素材,透過GauGAN也能輕鬆產生如真實般的圖片 這兩張圖原本是一連串動畫,透過左邊的不同素描,即可產生出如電影般的場景。不過劉洺堉表示目前的模型下,由於圖是個別依照原素材產生的,因此像是左圖的光澤與波浪是沒有連續性的,但可以先給導演或是製片一個方向,而這部份未來也是有機會克服的
這兩張圖原本是一連串動畫,透過左邊的不同素描,即可產生出如電影般的場景。不過劉洺堉表示目前的模型下,由於圖是個別依照原素材產生的,因此像是左圖的光澤與波浪是沒有連續性的,但可以先給導演或是製片一個方向,而這部份未來也是有機會克服的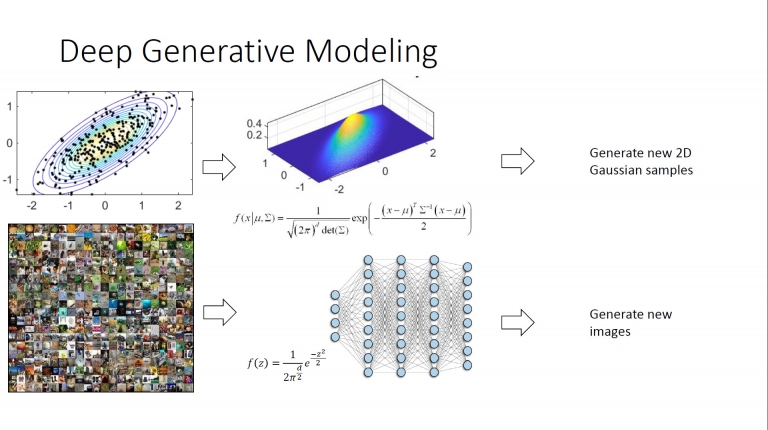 深度生成模型。上述是一般的原始圖像搭配亂數點,套用在三維圖像模型,可生成新的2D高斯模型。同理,下方的原始照片,透過AI運算,即可產生新的影像
深度生成模型。上述是一般的原始圖像搭配亂數點,套用在三維圖像模型,可生成新的2D高斯模型。同理,下方的原始照片,透過AI運算,即可產生新的影像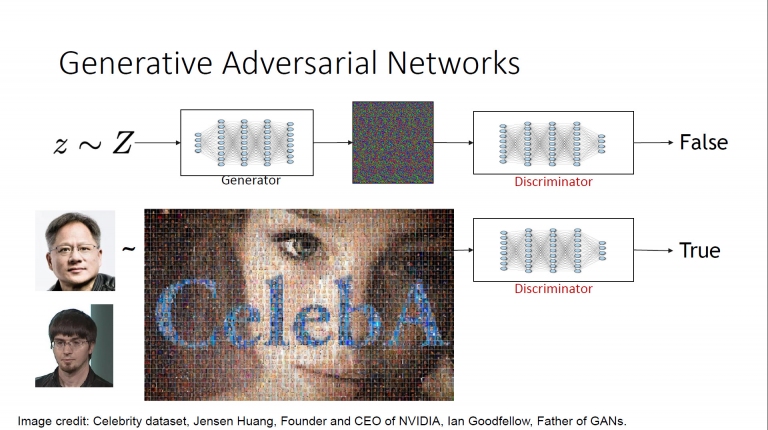 GAN (生成對抗網路)的模型就是,上述的圖片表示在沒有原始圖像時,產生器(Generator)只能產出無意義的亂碼圖,此時經過判別器(Discriminator)判定因為沒有人頭像,所以失敗!這樣就必須重新生成。而下方是提供各種原始頭像圖,經過產生器產生出我們規定想要的圖片後,經由判別器判定為「真」,代表成功生成。
GAN (生成對抗網路)的模型就是,上述的圖片表示在沒有原始圖像時,產生器(Generator)只能產出無意義的亂碼圖,此時經過判別器(Discriminator)判定因為沒有人頭像,所以失敗!這樣就必須重新生成。而下方是提供各種原始頭像圖,經過產生器產生出我們規定想要的圖片後,經由判別器判定為「真」,代表成功生成。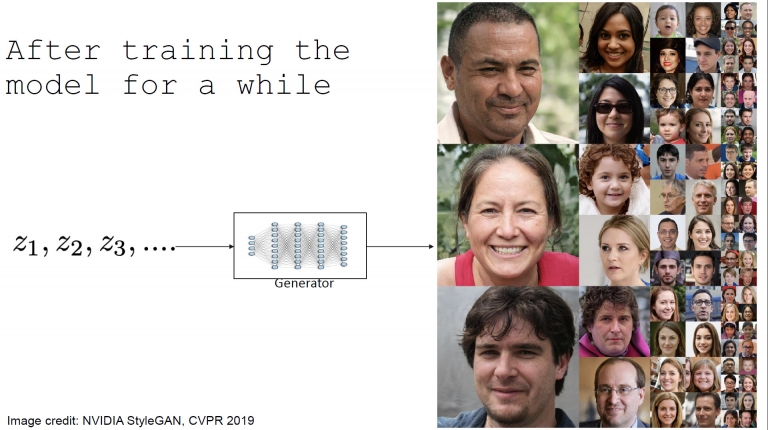 當原始人像取樣圖越多的時候,透過產生器的取樣,即可生成出各式各樣的臉譜與表情(右邊的照片都是電腦生成的,不是真實世界拍攝的人臉哦!)
當原始人像取樣圖越多的時候,透過產生器的取樣,即可生成出各式各樣的臉譜與表情(右邊的照片都是電腦生成的,不是真實世界拍攝的人臉哦!) 條件式GAN的模型,就是如上述的模型,而取樣則是依照不同設定條件來取樣
條件式GAN的模型,就是如上述的模型,而取樣則是依照不同設定條件來取樣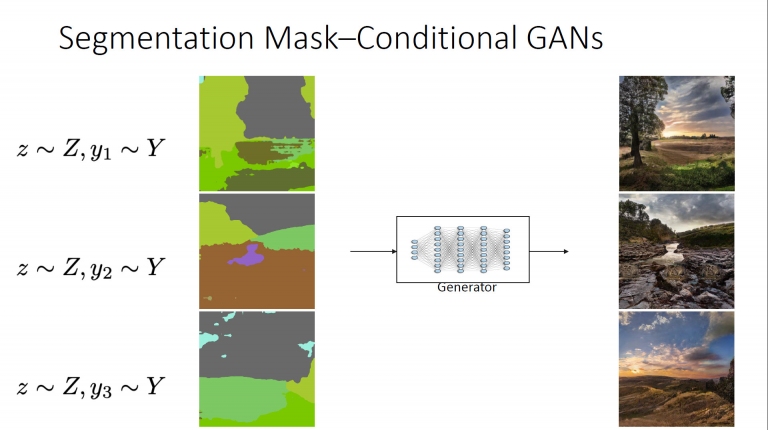 而NVIDIA條件式GAN的模型,就是以分割圖遮罩(Segmentation Mask)作法,z為原始圖庫,y為設定條件。例如上圖的綠色區設定成樹木、淺綠區設定成草地、灰色區為天空,透過產生器之後,即可生成如右上圖那樣的場景。以下類推!
而NVIDIA條件式GAN的模型,就是以分割圖遮罩(Segmentation Mask)作法,z為原始圖庫,y為設定條件。例如上圖的綠色區設定成樹木、淺綠區設定成草地、灰色區為天空,透過產生器之後,即可生成如右上圖那樣的場景。以下類推!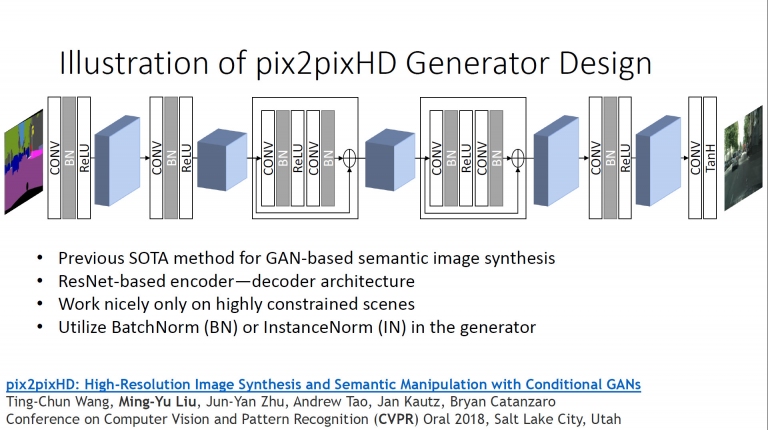 這是pix2pixHD (圖素點轉成高清圖素)的產生器設計模型,更多細節可參考這裡的白皮書
這是pix2pixHD (圖素點轉成高清圖素)的產生器設計模型,更多細節可參考這裡的白皮書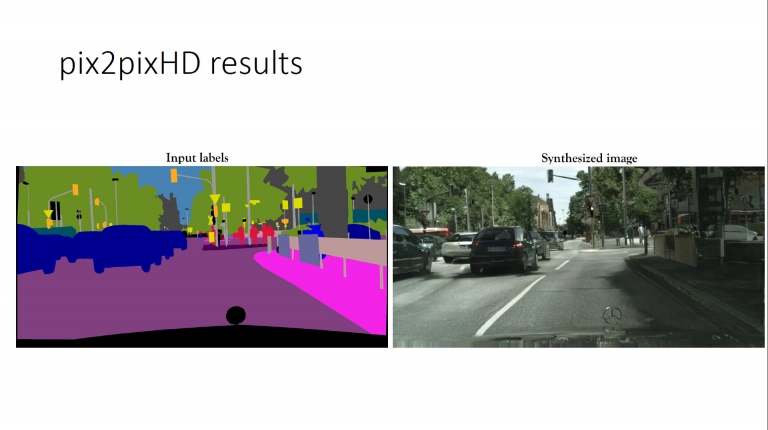 左邊是給予一些標記,右邊則是合成出來的圖片
左邊是給予一些標記,右邊則是合成出來的圖片 這些也都是條件式GAN的模型與生成圖片範例
這些也都是條件式GAN的模型與生成圖片範例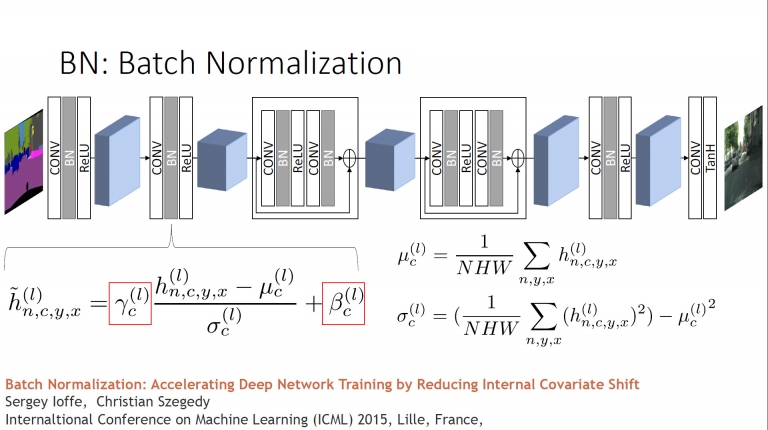 說到這裡,就不得不先提到BN (批次正規化),這原先是由Google在2015年提出,是一種深度學習網路的訓練技巧之一,可以加快模型的收斂速度,提升效能。這裡是BN的模型簡介
說到這裡,就不得不先提到BN (批次正規化),這原先是由Google在2015年提出,是一種深度學習網路的訓練技巧之一,可以加快模型的收斂速度,提升效能。這裡是BN的模型簡介 為什麼GauGAN要使用到BN模型,因為一開始的假設,是要減少協方差內部活動的轉變,如右上沒使用BN時,生成的圖片會變得很奇怪,採用BN後,表面變得比較單一光滑且單純。因此新的假設就是:讓風景照潤飾得更平滑,並促使權重空間往長度方向做去耦合,讓收斂速度更快
為什麼GauGAN要使用到BN模型,因為一開始的假設,是要減少協方差內部活動的轉變,如右上沒使用BN時,生成的圖片會變得很奇怪,採用BN後,表面變得比較單一光滑且單純。因此新的假設就是:讓風景照潤飾得更平滑,並促使權重空間往長度方向做去耦合,讓收斂速度更快 不過使用BN模型也有些小問題,就是往往會洗掉一些語意輸入訊息,導致生產圖片的畫質下降(參考上述的圖)
不過使用BN模型也有些小問題,就是往往會洗掉一些語意輸入訊息,導致生產圖片的畫質下降(參考上述的圖) 因此必須搭配SPADE技術,來讓生成畫面更接近原始語意所要表達的重點。例如這裡的說明,若單獨透過pix2pixHD之下,生成的圖就可能出現灰色的狀況(語意被洗掉了),而搭配SPADE之後,就能清楚告訴產生器要生成的正確圖像
因此必須搭配SPADE技術,來讓生成畫面更接近原始語意所要表達的重點。例如這裡的說明,若單獨透過pix2pixHD之下,生成的圖就可能出現灰色的狀況(語意被洗掉了),而搭配SPADE之後,就能清楚告訴產生器要生成的正確圖像 再搭配「分割圖遮罩」技術,通常包含了超大單一區域的範圍與語意描述,即可生成更精準的目標圖像
再搭配「分割圖遮罩」技術,通常包含了超大單一區域的範圍與語意描述,即可生成更精準的目標圖像 這是BN和SPADE的公式模型比較。且空間變化量,取決於輸入的分割圖遮罩,而正規化所洗掉的資訊還可透過Gamma值和Beta值補貼回來
這是BN和SPADE的公式模型比較。且空間變化量,取決於輸入的分割圖遮罩,而正規化所洗掉的資訊還可透過Gamma值和Beta值補貼回來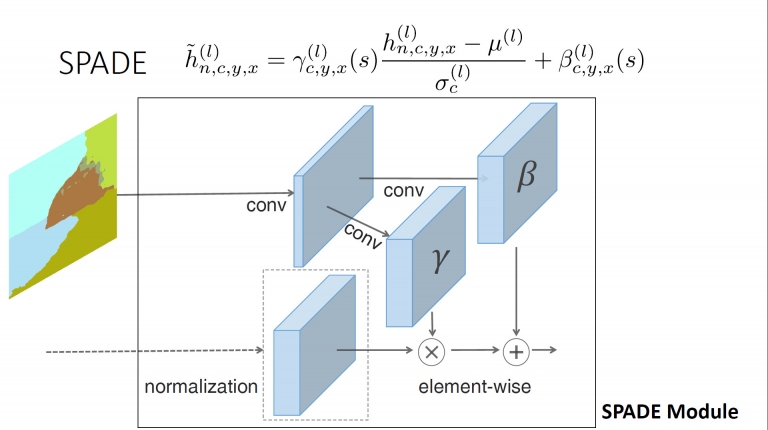 這就是SPADE的模組簡述
這就是SPADE的模組簡述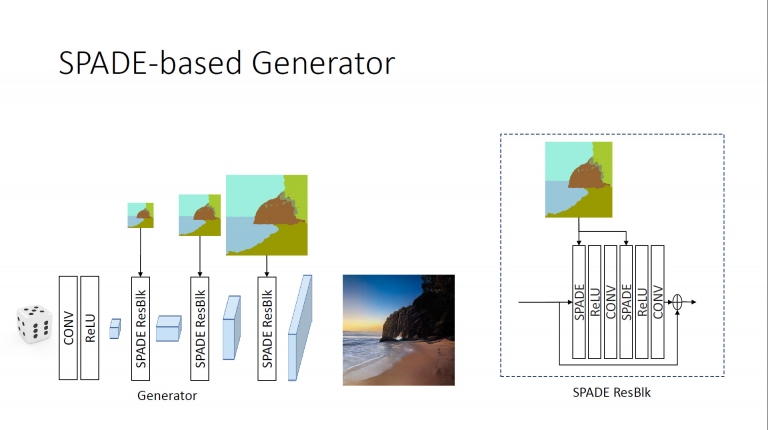 透過上述的模型,發展出以SPADE為主的圖像產生器
透過上述的模型,發展出以SPADE為主的圖像產生器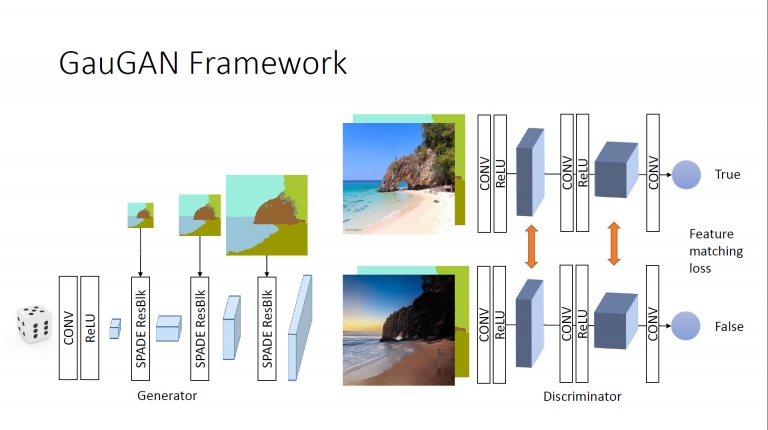 而NVIDIA的GauGAN,便是基於SPADE為基礎的框架
而NVIDIA的GauGAN,便是基於SPADE為基礎的框架 如此一來,只要設定好分割圖遮罩,即可生成出用戶想要的目標照片。並不限定風景照,就算是室內照片,也都能輕鬆繪製
如此一來,只要設定好分割圖遮罩,即可生成出用戶想要的目標照片。並不限定風景照,就算是室內照片,也都能輕鬆繪製 室外風景,也都能如所需要來生成
室外風景,也都能如所需要來生成 當然動物也能完美生成
當然動物也能完美生成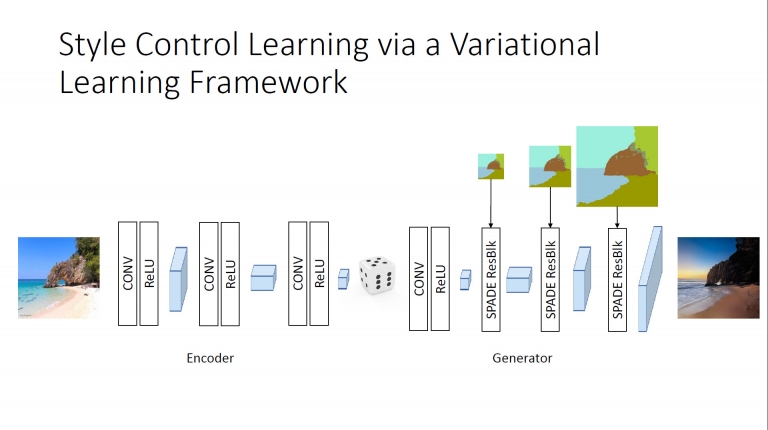 透過可變式學習框架,來進行樣式控制學習
透過可變式學習框架,來進行樣式控制學習 因此只要有標記和地面真實性,就能生成出不同的目標圖片 (有暗有明)
因此只要有標記和地面真實性,就能生成出不同的目標圖片 (有暗有明)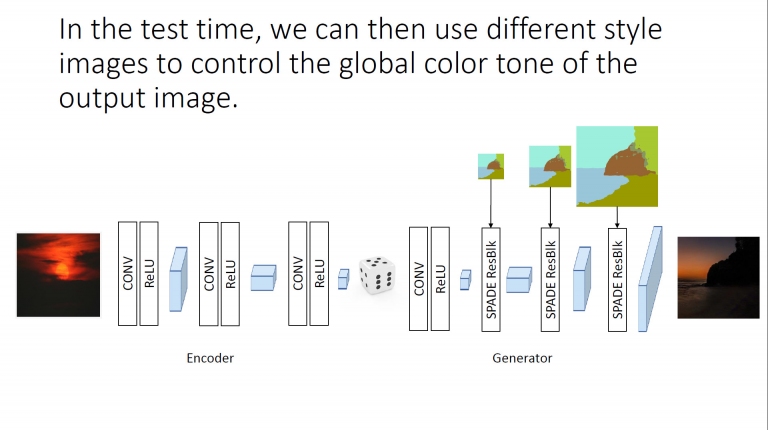 此外在測試過程中,我們可以使用不同樣式影像來控制輸出圖的全域色調
此外在測試過程中,我們可以使用不同樣式影像來控制輸出圖的全域色調 這裡就是引用原始圖片的色調,來為輸出圖形的色調進行調整,成為GauGAN最終的輸出圖片
這裡就是引用原始圖片的色調,來為輸出圖形的色調進行調整,成為GauGAN最終的輸出圖片以上,就是GauGAN所使用到的各種模型與深度學習網路。在圖片的大數據中,劉洺堉表示,目前NVIDIA GanGAN的雲端資料庫照片共有超過500萬張,這些皆是來自flickr或是其他有授權的圖片。而每當使用者將素描語意檔上傳並送至NVIDIA的GauGAN伺服器進行分析之後,GauGAN會從已經透過過深度學習訓練後的100萬張圖當中,挑出最符合語意的照片素材,以合成出最適合的照片組成,最後再調整色調,讓整張照片看起來沒問題之後,再回傳給使用者。
最後,提供與GauGAN與PetSwap的相關網站,讓使用者親自去體驗看看吧!
● GauGAN遊樂場: http://nvidia-research-mingyuliu.com/gaugan/
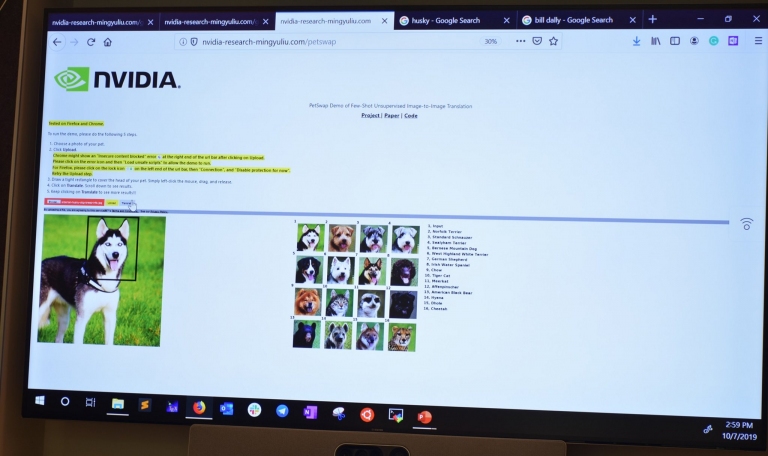 另外的PetSwap,可以輸入一個原始動物照片,然後圈選頭部範圍,就能產生出其他不同動物,但表情類似的照片,讓AI應用更加有趣!
另外的PetSwap,可以輸入一個原始動物照片,然後圈選頭部範圍,就能產生出其他不同動物,但表情類似的照片,讓AI應用更加有趣!● PetSwap遊樂場: http://nvidia-research-mingyuliu.com/petswap
- 發表您的看法
請勿張貼任何涉及冒名、人身攻擊、情緒謾罵、或內容涉及非法的言論。
請勿張貼任何帶有商業或宣傳、廣告用途的垃圾內容及連結。
請勿侵犯個人隱私權,將他人資料公開張貼在留言版內。
請勿重複留言(包括跨版重複留言)或發表與各文章主題無關的文章。
請勿張貼涉及未經證實或明顯傷害個人名譽或企業形象聲譽的文章。
您在留言版發表的內容需自負言論之法律責任,所有言論不代表PCDIY!雜誌立場,違反上述規定之留言,PCDIY!雜誌有權逕行刪除您的留言。
最近新增
- AI數位轉型找華碩!ASUS EXPERTHUB共好生態圈上線
- LG WashTower65公分窄身新登場 洗乾各18公斤大容量一次到位! 洗乾全AI、雙變頻熱泵 省時節能兼顧精緻護衣
- NVIDIA 推出新款 Jetson Thor 電腦,推動主流機器人與邊緣 AI 發展 由NVIDIA Blackwell 架構驅動的全新 T3000 與 T2000 模組,搭配 NVIDIA Jetson 軟體的記憶體最佳化功能與代理技能,協助合作夥伴與客戶將先進的機器人、視覺 AI 與邊緣工作負載,移轉至精巧且節能的系統
- 日本企業與新創以 NVIDIA Nemotron 開放式模型打造產業專屬 AI
- AI 不再只是回答問題!台灣駭客年會聚焦 Agentic AI 時代資安新挑戰 全球駭客與資安專家齊聚台北 從 AI 安全、後量子密碼到工控防護,共探下一世代資安韌性
- OVO發表品牌理念「快樂科技」及全球首創可K歌三雷射超短焦投影機「雷射派對劇院」SS2 嗨嗨平台家電租賃年度新品上架,24期0利率期滿免還再加碼延保1年,高階產品輕鬆入手
- 「坐」擁絕對優勢!XPG NIMBUS 和 NIMBUS PLUS 電競椅全新登場 以頂級人體工學打造極致電競與舒適辦公體驗
- GIGABYTE 攜手 Dcard 打造期間限定電競體驗基地
- 贊助百萬首獎力挺影視產業!華碩ProArt精彩視界綻放台北電影節 全新4K QD-OLED專業螢幕PA27USD / PA279CDV乘勝追擊!
- 以高度模組化,為Micro-ATX緊湊機殼帶來大膽進化!MONTECH君主科技推出全新TEN機殼
- Synology 推出最新備份專用機 DP5200, 為成長中企業帶來全方位資料保護
- 迎廣推出業界首創長虹玻璃景觀機殼 L50 BREEZE 結合 AWWA PureTone環境燈光打造 Lifestyle PC 新體驗
最多人點閱
- GIGABYTE GeForce GTX 1070 Xtreme Gaming實測開箱,電競級顯示卡中的頂尖之作!
- Seagate IRONWOLF 10TB機械硬碟實測開箱,氦氣填充那嘶狼守護者NAS HDD
- 「浦科特 PLEXTOR S2C 512GB SSD」實測開箱,超值型固態硬碟中的優質好貨!
- 洋垃圾神器,Xeon E5-2670實測開箱大作戰!
- MSI CORE FROZR L CPU散熱器實測開箱,微星電競產品再添新兵
- MSI GeForce GTX 1060 GAMING X 6G實測開箱,玩家級電競顯示卡中的神兵利器!
- ASUS ROG STRIX-GTX1080-O8G-GAMING開箱實測,旗艦三風扇電競顯示卡中的頂尖之作!
- MSI GeForce GTX 1080 GAMING X 8G實測開箱,史上最強大Pascal自製顯示卡全面來襲!
- 淘寶網洋垃圾再顯神威,1999元買到8核心16執行緒Xeon E5-2670神器級處理器!
- MSI GeForce GTX 1050 Ti GAMING X 4G實測開箱,中階電競顯示卡中的玩家精品!
- 微星MSI Aegis X-026TW快打旋風V同梱版實測開箱,VR電競桌機的頂尖之作!
- 捉對廝殺:AMD Ryzen 2200G/2400G VS Intel Core i3-8100/i5-8400

